







阿里云Databricks数据洞察
立即咨询
 首页
首页 阿里云Databricks数据洞察
阿里云Databricks数据洞察 产品优势功能特性
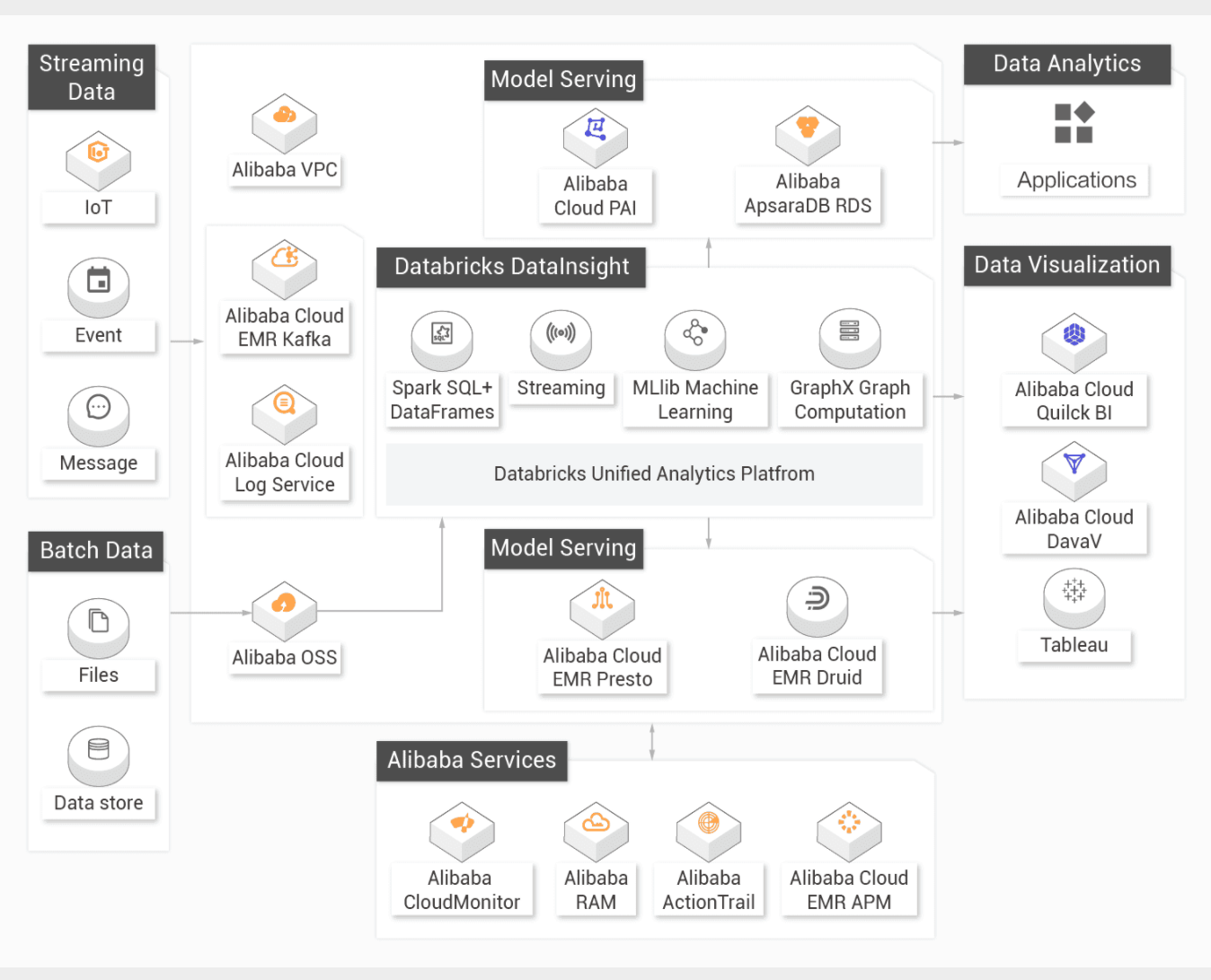
产品优势功能特性Databricks数据洞察包含了完整的社区版Spark的功能和特性,全面兼容Apache Spark。 Databricks数据洞察包含以下组件:
产品架构Databricks数据洞察构建在ECS之上,使用阿里云对象存储服务(OSS)为核心存储。本文介绍Databricks数据洞察的产品架构。 存储访问加速层方便您可以像操作HDFS上的数据一样访问OSS上的数据。 目前,Databricks数据洞察提供了两种执行Spark作业的方式,包括通过Notebook或者在项目空间里新建Spark作业。同时,Databricks数据洞察还提供了监控告警、元数据管理、权限管理等功能,方便您对集群资源进行管理。

产品功能应用场景—流批一体数据仓库统一的大数据管理平台,从上游数据抽取到下游数据分析,贯穿整个数据分析工作流。自动扩缩容,免运维,降低运维成本。
应用场景—机器学习简化机器学习生命周期,快速进行模型测试、实验、以及生产部署,并可视化结果。

产品推荐

阿里云双碳能耗云-工业园区双碳解决方案,充分利用物联网和大数据技术,看到园区碳排情况,增加“双碳”管理功能, “一图掌 控”绿色低碳发展。以低碳发展为准绳,探索园区减污降碳协同治理,分类精准进行产业调整,促进园区高质量发展。实现园区能源供给低碳、生产节能降碳、绿色建筑脱碳、办公生活低碳化。

VMware虚拟机管家,同一界面统一管理多vCenter环境的数据中心、集群、主机、虚拟机、网络和存储资源的操作、资源使用和数据展现等。适用于所有VMware vSphere虚拟化环境!VMware管家提供批量虚拟机资源创建、开关机、迁移等日常操作能力。


PingCode 企业级知识库管理工具,它采用多层级设计,适配多场景知识管理。画板图形、表格丰富创作形式,深度关联产研工作,直接创造价值。还能通过标准 Rest API 集成其他系统,提供广泛知识支撑。



