






魔音工坊AI配音平台
立即咨询
 首页
首页 出门问问TTS承接平台-魔音工坊 | 产品介绍视频
出门问问TTS承接平台-魔音工坊 | 产品介绍视频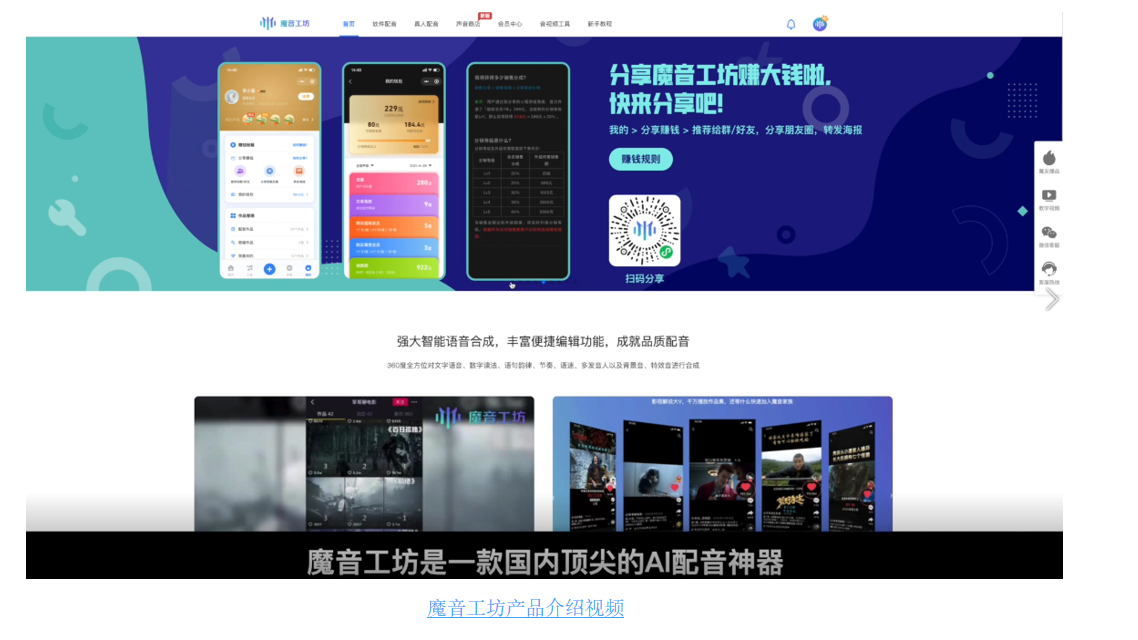 出门问问TTS承接平台-魔音工坊 | 专业的AI配音软件
出门问问TTS承接平台-魔音工坊 | 专业的AI配音软件  强大的音频合成编辑功能
强大的音频合成编辑功能 首创声音编辑器,可实现多音字、重度、停顿调节、连续等功能,支持局部变速、变音、多人配音,自带版权BGM、音效等。
 1000+发音人满足用户多样性需求
1000+发音人满足用户多样性需求 100+方言配音、外语配音,支持老人、小孩等不同年龄、不同音色的声音。
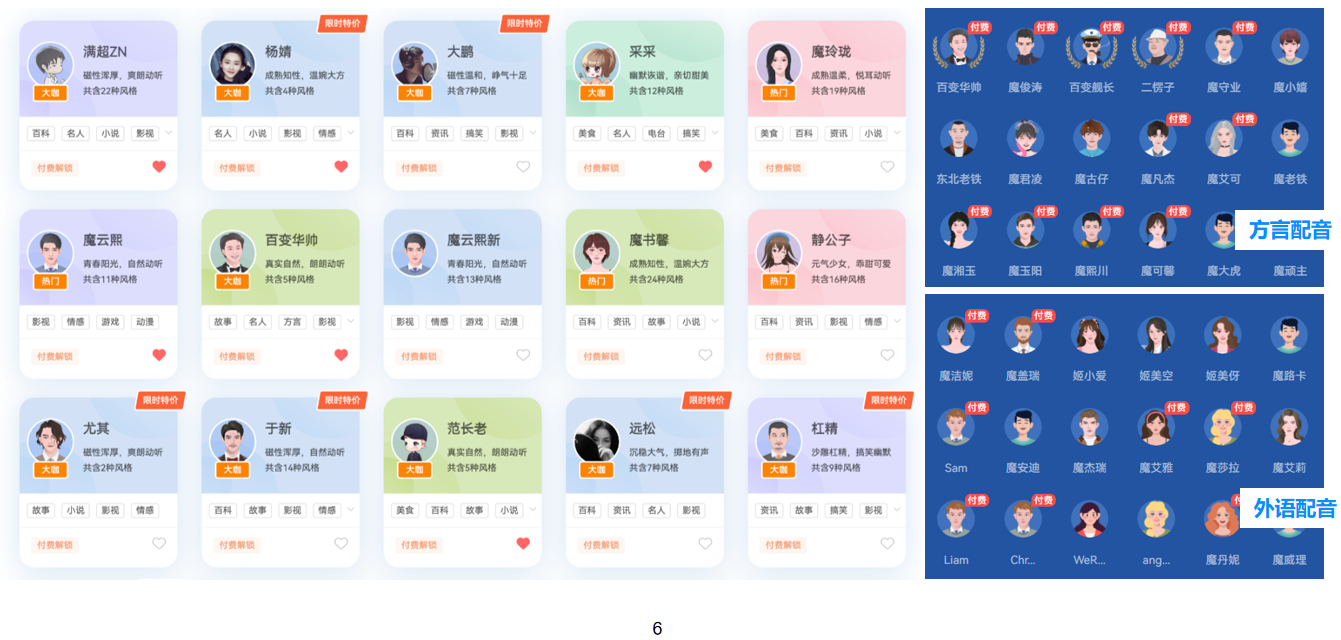 覆盖喜怒哀乐四大维度情绪,让声音更有温度
覆盖喜怒哀乐四大维度情绪,让声音更有温度 同一发音人可支持二十多种情绪表达。
 众多大咖入驻魔音
众多大咖入驻魔音  多元化的解决方案
多元化的解决方案  全新的后付费合作模式
全新的后付费合作模式  领先的声音定制服务魔音工坊声音克隆八大优势 魔音工坊声音克隆八大应用场景 声音转换,音色转化成其他发音人
领先的声音定制服务魔音工坊声音克隆八大优势 魔音工坊声音克隆八大应用场景 声音转换,音色转化成其他发音人 说话人转换:保留「原说话人」的声调、韵律、停顿等特色,音色转换成「目标人」音色。
 实时变声功能&声纹识别-听音识人
实时变声功能&声纹识别-听音识人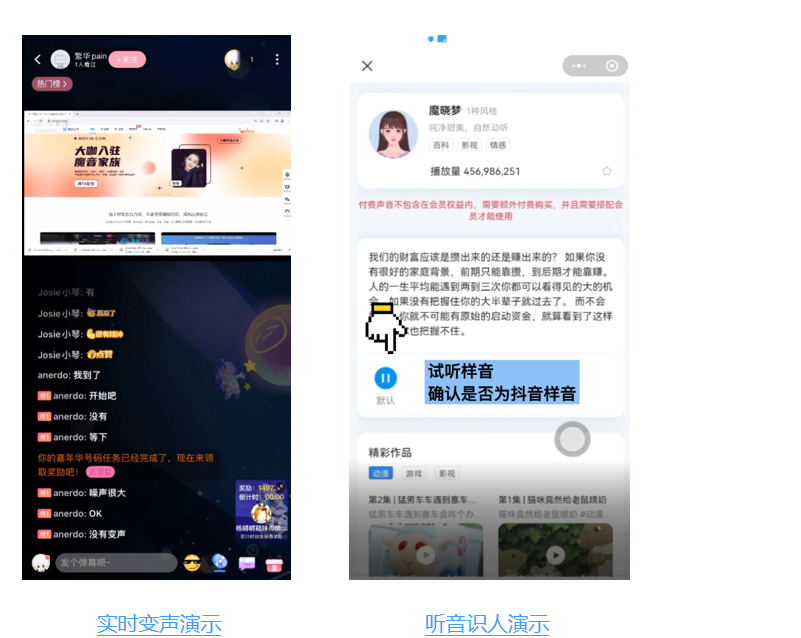 Dupdub(魔音海外版):助力短视频出海
Dupdub(魔音海外版):助力短视频出海  Overview of DupDub
Overview of DupDub  品牌合作案例
品牌合作案例  品牌合作案例-微信读书
品牌合作案例-微信读书 
出门问问TTS技术优势
1-TTS端到端语音合成引擎,合成效果媲美真人 业界领先的完全端到端模型,合成效果高度接近真人(MOS:4.488) 端到端语音合成方案MeetHiFiVoice (Mobvoi End-to-End TTS HiFiVoice)MOS是通信术语,值常以衡量通信系统语音质量的重要指标, MOS值在4.0-5.0区间,音频级别为优,表示听的清楚,延迟小,交流顺畅。
 领先的韵律准确率,多音字准确率业界Top 1
领先的韵律准确率,多音字准确率业界Top 1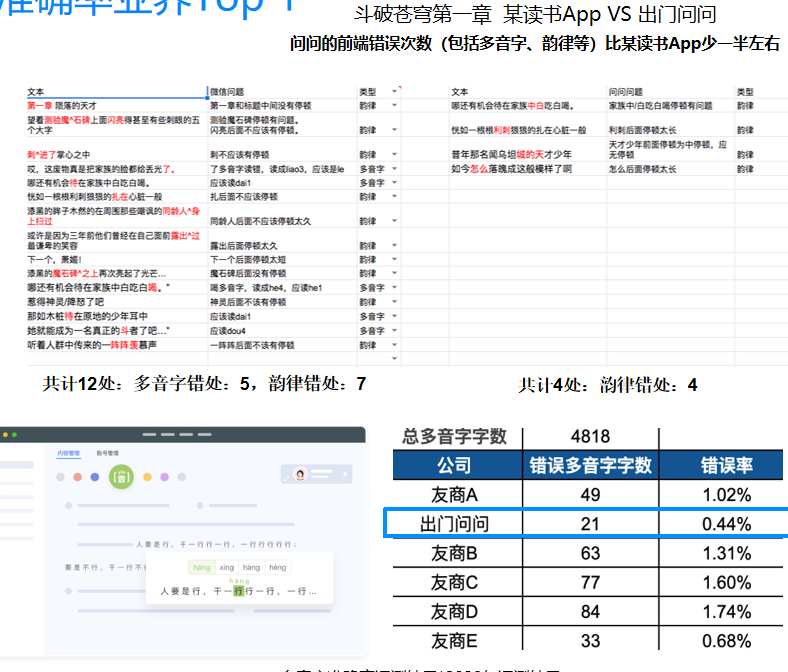
 丰富的语气/语调合成和重读/拖音功能,增强声音的表现力拟人化TTS,让声音更自然
丰富的语气/语调合成和重读/拖音功能,增强声音的表现力拟人化TTS,让声音更自然 情感语音合成
情感语音合成 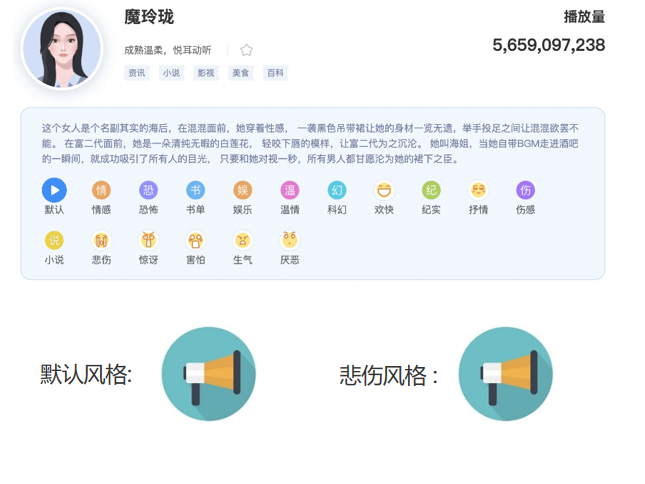
 情感强度控制
情感强度控制  跨语种语音合成
跨语种语音合成  歌唱合成&歌唱合成迁移
歌唱合成&歌唱合成迁移  实时声音转换
实时声音转换  角色迁移
角色迁移  声音克隆
声音克隆  高品质声音输出
高品质声音输出
 愿景:定义下一代人机交互,让人和机器的交互更自然
愿景:定义下一代人机交互,让人和机器的交互更自然 



 浓厚的技术基因 商业逻辑架构:以AI算法为切入点,赋能各行各业 AI算法:基于神经网络的自主全栈式AI算法
浓厚的技术基因 商业逻辑架构:以AI算法为切入点,赋能各行各业 AI算法:基于神经网络的自主全栈式AI算法 核心技术能力:语音交互
核心技术能力:语音交互 商业落地:全球领先的AI可穿戴设备
商业落地:全球领先的AI可穿戴设备  AI可穿戴:一流的国际产业合作伙伴
AI可穿戴:一流的国际产业合作伙伴  商业落地:智能车载(德国车规级前装语音助手)
商业落地:智能车载(德国车规级前装语音助手) 出门问问车载前装“离线在线融合语音助手”落地多款大众主力车型
 商业落地:AI算法license落地
商业落地:AI算法license落地 智能手表和真无线蓝牙耳机是高增长、高天花板的市场,将持续成为ToC增长引擎。

产品推荐


腾讯云慧眼人脸核身提供各类认证功能模块,所有功能模块8折起!同时,云巴巴携手腾讯云带来云产品钜惠,十大类别,百余款云产品限时优惠,更有iphone12、大额京东卡等礼品拿到手软,先到先得。

达观数据客户体验数据分析平台,打通以客户为中心的数智化服务平台,建立观点意见标签分类与净值分析体系、动态捕捉个性化用户需求、建立产品服务及质量溯源数据湖、承载多渠道客户意见洞察助力全生命周期管理。

追一科技多模态数字人Face,融合计算机视觉、语音识别、自然语言处理(NLP)等多种人工智能技术,对人体的形态、表情和 动作进行模拟仿真,打造出高度拟人化的虚拟数字形象,能像真人 般与人互动沟通,带来全新的感官体验。
数字化社区
视频
文章



