






思必驰手机音频解决方案
 首页
首页 智能电子产品特征
智能电子产品特征低功耗 | 小型化 | 持续监听 | 复杂场景抗噪 | 近场交互
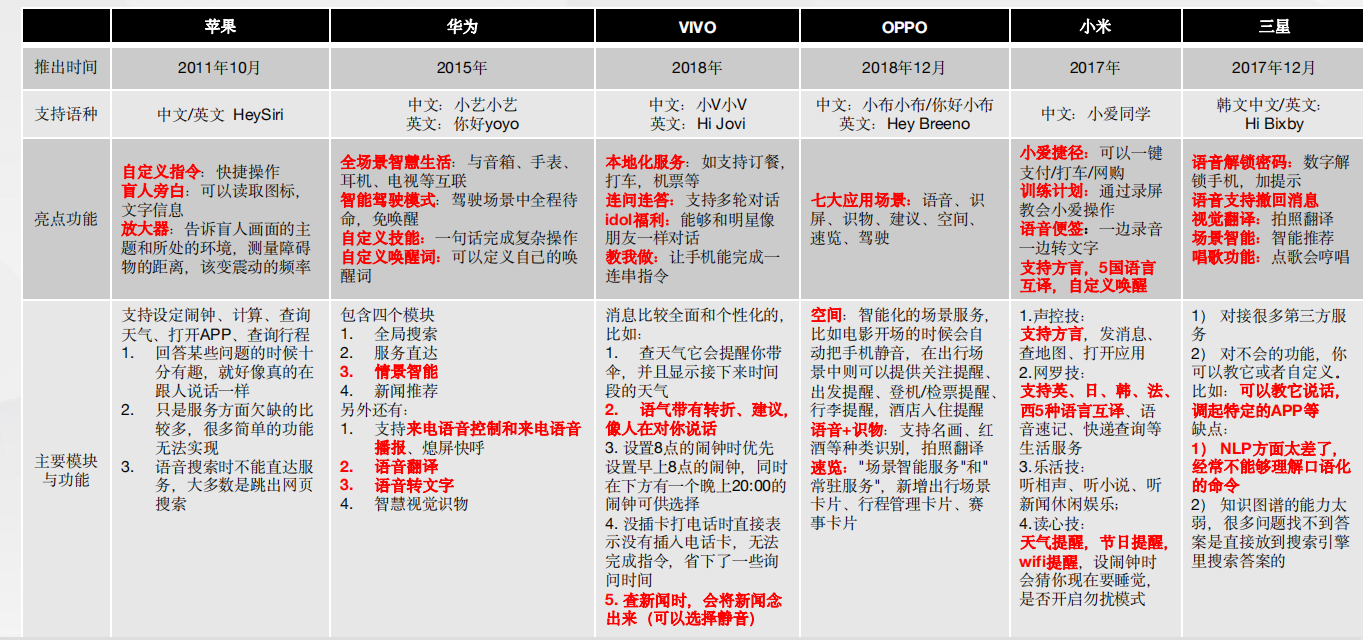
智能电子语音解决方案架构图 智能手机行业竞争—芯片、屏幕、摄像、充电、音质是营销重点
智能手机行业竞争—芯片、屏幕、摄像、充电、音质是营销重点 语音助手是各家提升人性化智能化,打造私人助理的重要途径
语音助手是各家提升人性化智能化,打造私人助理的重要途径语音应用:盲人/聋哑人应用、智能场景识别、自定义唤醒、语音解锁密码、与可穿戴设备联动、全双工人机对话、语音转文本、方言与翻译、语音+图像识物。
 低功耗唤醒与多级校
低功耗唤醒与多级校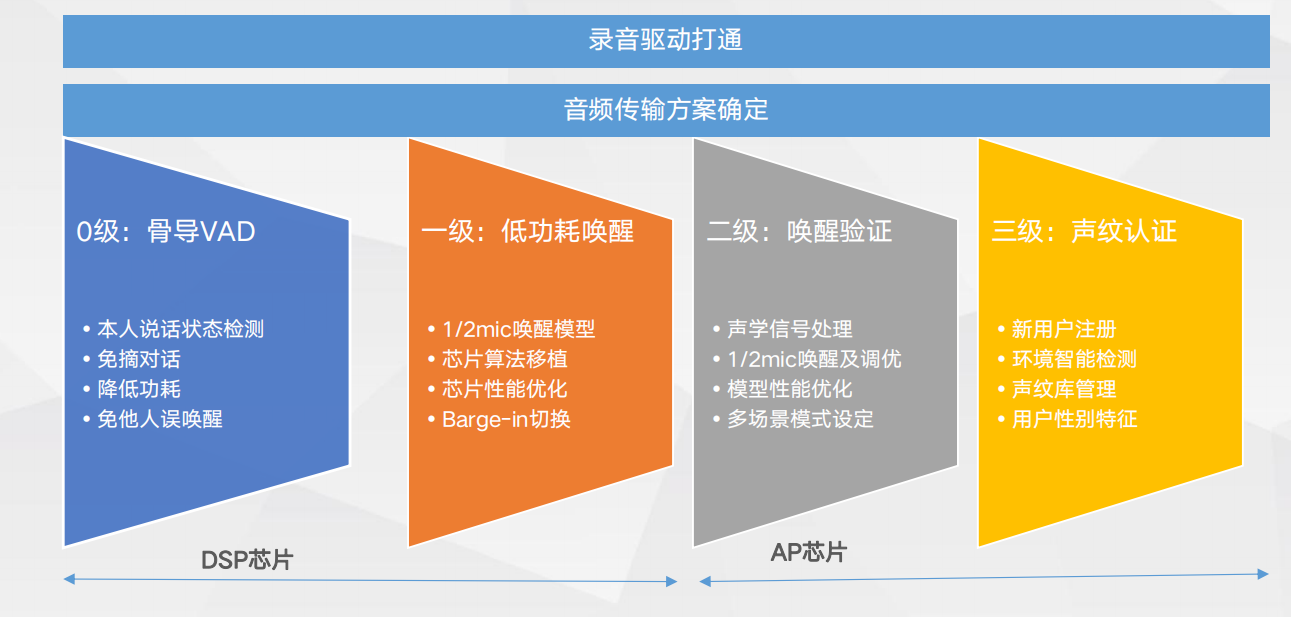 自定义唤醒
自定义唤醒低功耗自定义唤醒: 1. 唤醒模型大小:75k 2. 流程:手机端设定唤醒词,检查唤醒词合规性并计算阈值,开始声纹注册, 注册成功后将唤醒模型与声纹模型load到一级ADSP上 3. 测试场景:安静场景、家居场景。
 低功耗唤醒与多级校验
低功耗唤醒与多级校验 免唤醒命令控制
免唤醒命令控制背景:不再拘束于唤醒词,提供更自然的语音交互能力。在我们的日常生活中,不会和别人说话时每说一句话就叫对方名字一次,同样每次使用语音功能时都需要先呼叫车机的小名,有时真的会感觉心累;
使用场景:全局生效或者在应用内生效,如拍照摄影、游戏控制、音乐播控;
案例:
1. VIVO手机:拍照命令控制(拍照、茄子、Cheese)
2. 黑鲨手机:游戏控制命令词(打雷打雷、打药打药……)
3. 小米手机:来电控制命令词(接听电话、挂断电话)
4. 耳机:音乐播控命令词(增大音量、减小音量、上一首、下一首、播放音乐、暂停播放)
5. 手表:常用变盘操作指令(常用设置、运动设置、闹钟提醒……)
优势:
1. 资源占用低
2. 响应速度快
3. 准确率高
应用案例小米手机: 支持接打电话、控制APP 可定义VIVO手机: 通过声控控制拍照,包括中文和英文 分别是:拍照、茄子、Cheese。
 本地通用识别
本地通用识别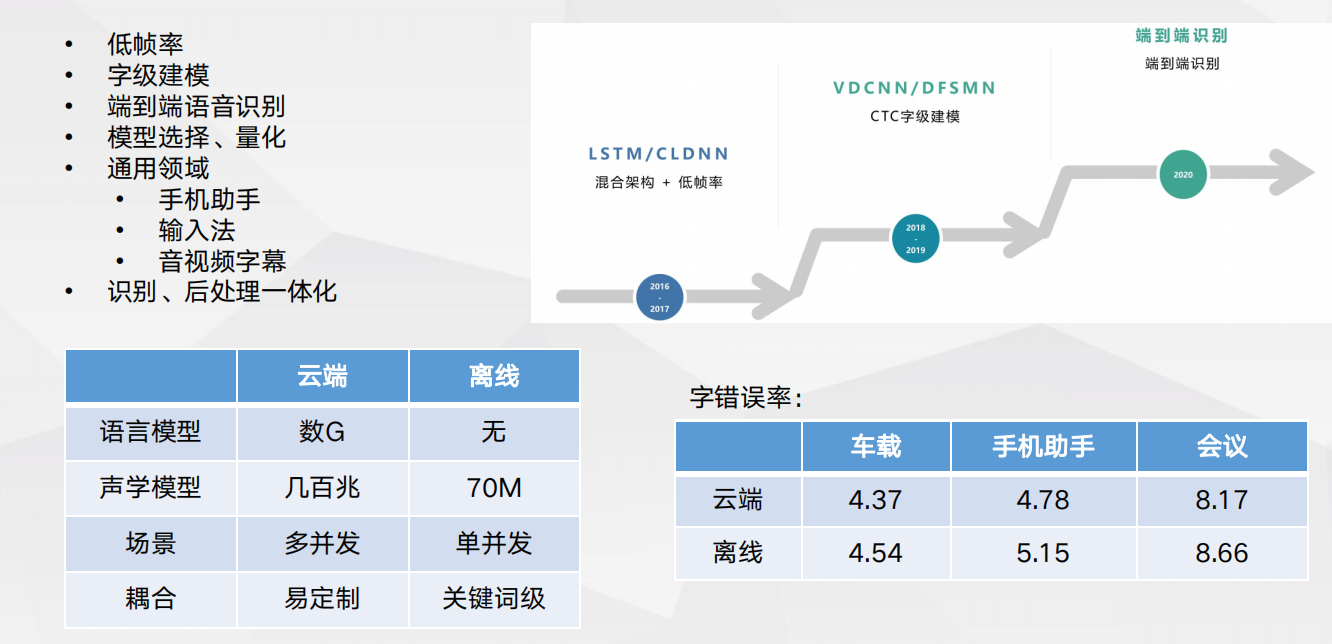 场景识别与声音事件检测
场景识别与声音事件检测 方言和重口音种类
方言和重口音种类 方言和重口音特性与性能
方言和重口音特性与性能 小语种
小语种 TTS 风格&情感合成
TTS 风格&情感合成
 TTS 声音复刻
TTS 声音复刻 TTS 本地合成
TTS 本地合成
 TTS 方言小语种
TTS 方言小语种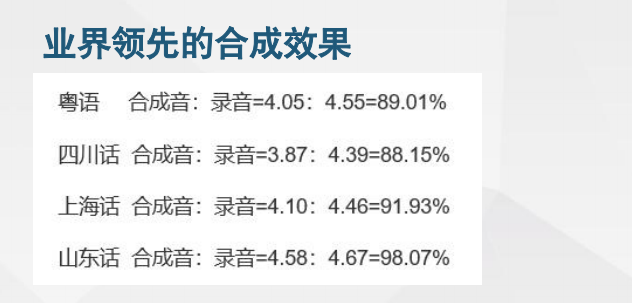 近场智慧降噪
近场智慧降噪 远场会议通话降噪
远场会议通话降噪主要由三个部分组成:回声消除、语音降噪、自动增益控制。 1. 回声消除采用传统控制和深度神经网络相结合的方案消除线性回声和非线性回声,能够在单讲 回声消除干净的情况下尽可能保留双讲人声。 2. 语音降噪部分利用麦克风阵列技术选取主要方向人声,再利用神经网络模型进行语音降噪,所 使用的网络模型包含了绝大多数会议场景噪声,如小会议室、大会议室、嘈杂办公室等等。 3. 自动增益控制是为了保证人声不会因为人与设备之间的距离增加而产生明显的音量变化。
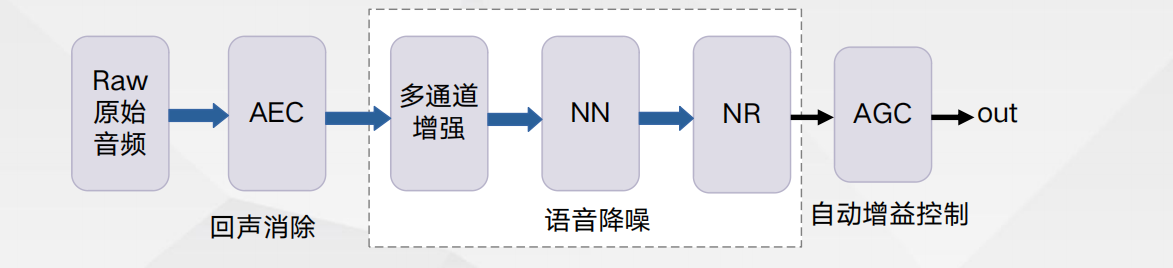 远场通话降噪-效果对比
远场通话降噪-效果对比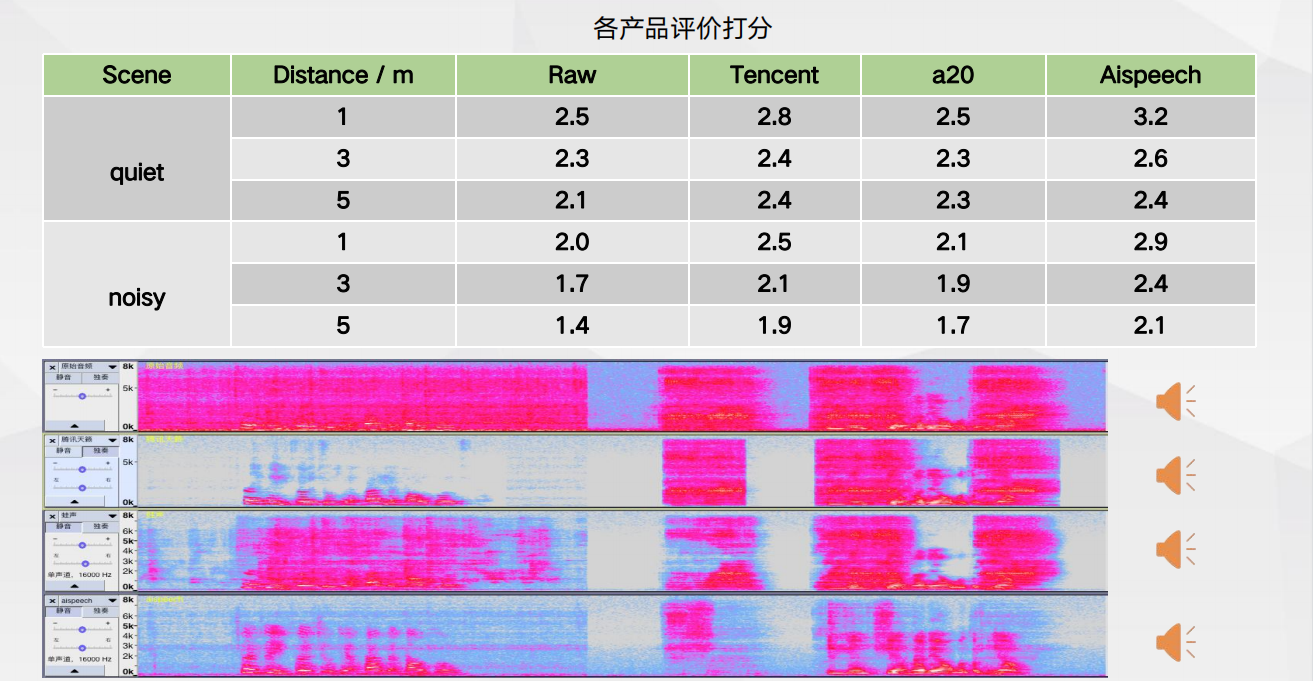 多种麦克风阵列
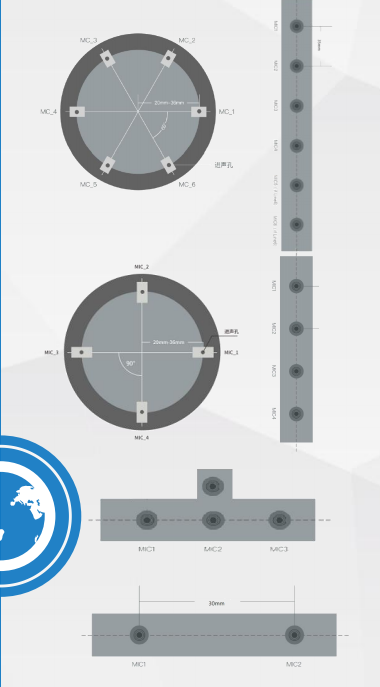
多种麦克风阵列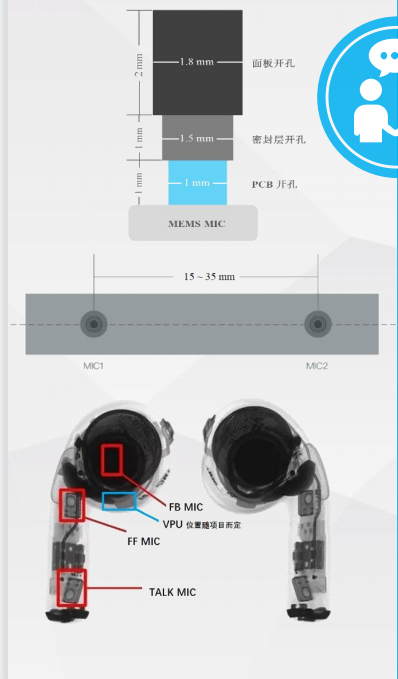
 结合声纹的目标人声提取
结合声纹的目标人声提取 1+N—跨设备声纹验证
1+N—跨设备声纹验证 1+N—融合声纹验证
1+N—融合声纹验证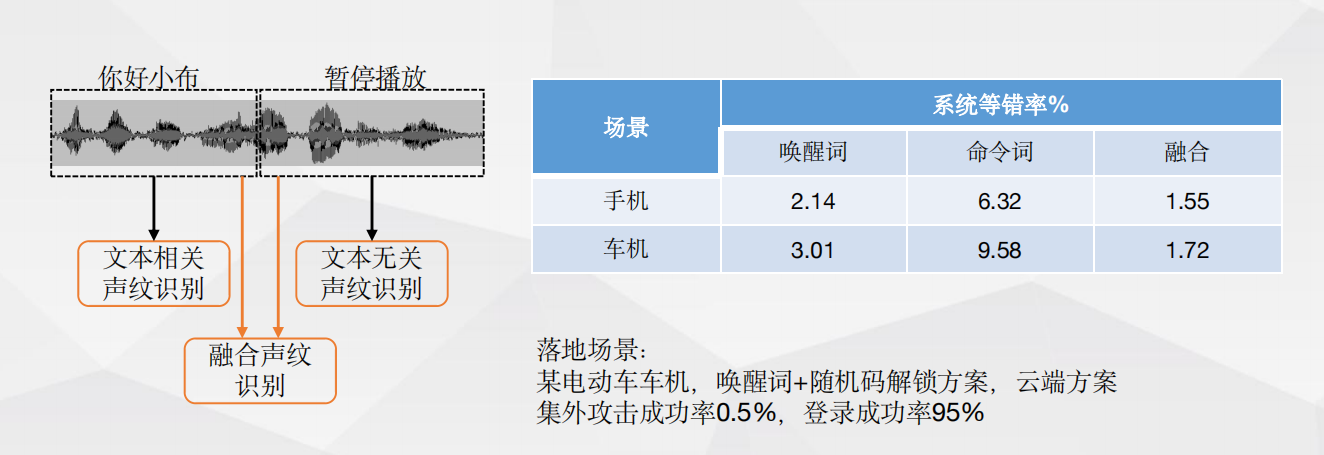 应用案例1+N—就近唤醒
应用案例1+N—就近唤醒 AI接听助理:自助转接+回应
AI接听助理:自助转接+回应 AI接听助理:C端灵活定制
AI接听助理:C端灵活定制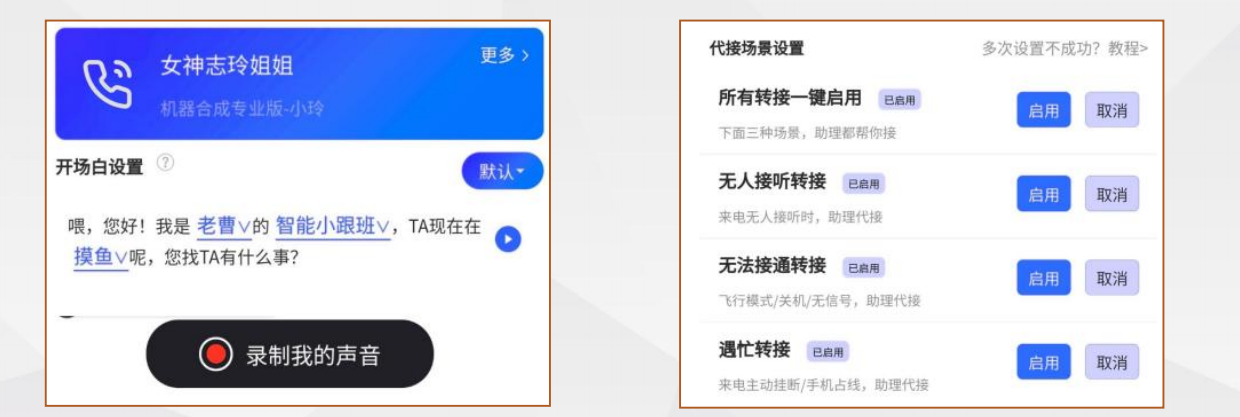 典型合作客户
典型合作客户
产品推荐







