
 可穿戴设备语音解决方案
可穿戴设备语音解决方案低功耗高性能 | 全场景降噪 | 差异化方案 | 一站式服务。
 自适应通话降噪-让 他/她 听清你的声音
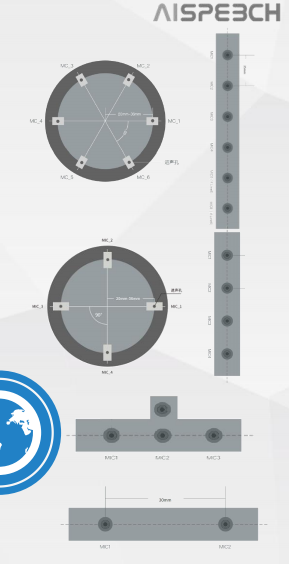
自适应通话降噪-让 他/她 听清你的声音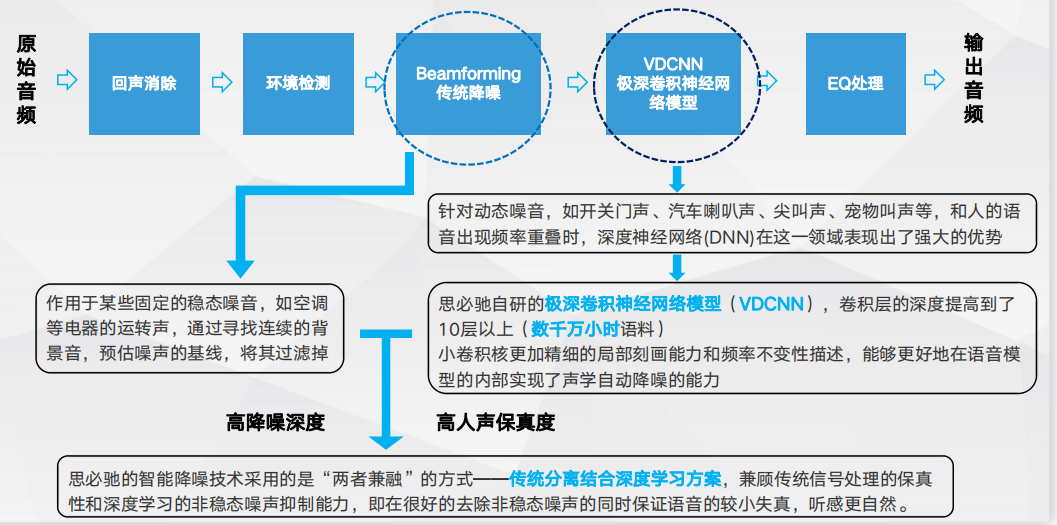 多种麦克风阵列
多种麦克风阵列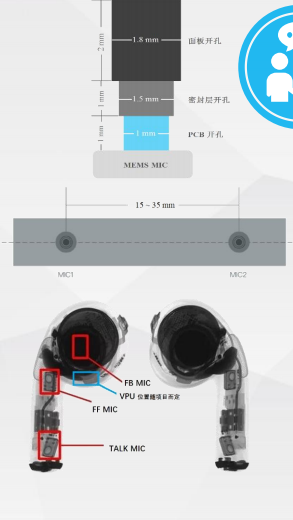
 耳机自适应通话降噪-三麦ENC 无惧风噪
耳机自适应通话降噪-三麦ENC 无惧风噪 耳机自适应通话降噪-骨导ENC 降噪中的战斗机
耳机自适应通话降噪-骨导ENC 降噪中的战斗机算法优势: 1. 骨导传感器提供的信号对高噪声场景(如运行的地铁、大风噪等)有着更好的消噪效果,通话无障碍; 2. 骨导传感器提供的音频能量集中在低频部分,通过算法DNN等调整校准,输出的处理音频人声保真度高, 不显得人声过于发闷; 3. 通过融合FF & talk mic的信息(如果有FB mic,也会参考FB mic 信号),结合深度学习算法,对稳态 与非稳态噪声消除好。
 耳机自适应通话降噪-双麦ENC
耳机自适应通话降噪-双麦ENC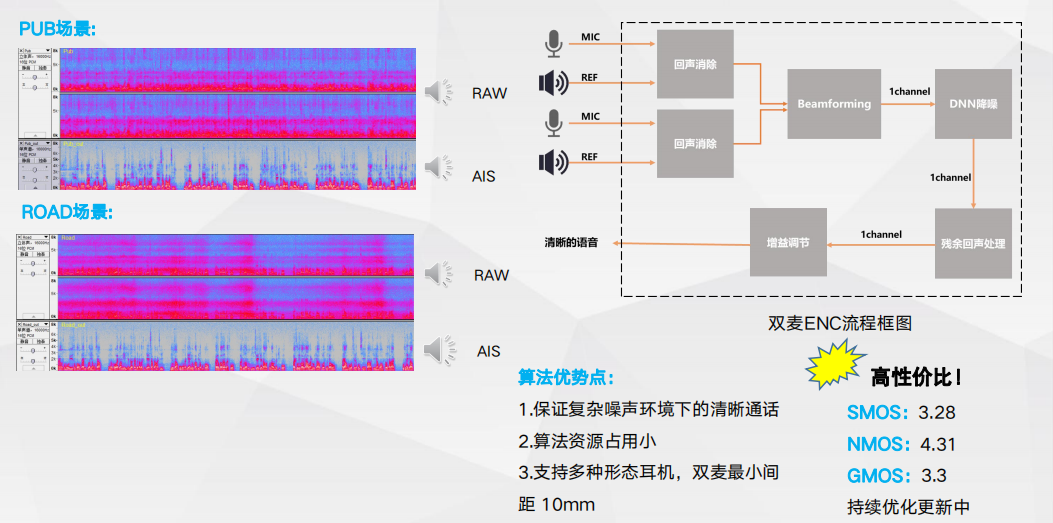 耳机自适应通话降噪-单麦
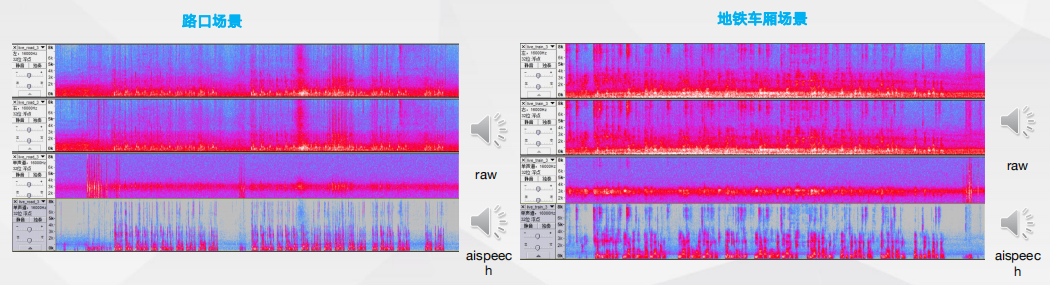
耳机自适应通话降噪-单麦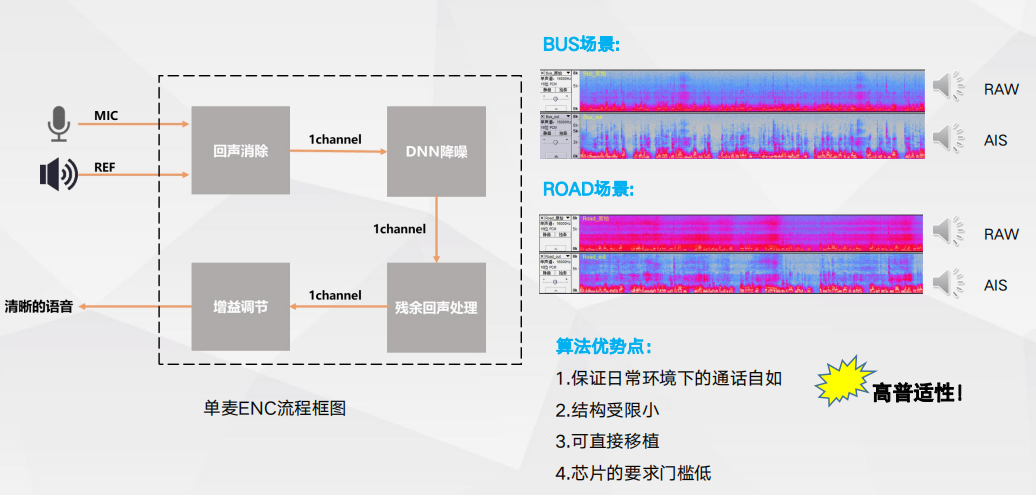 优秀的抗噪能力-无惧风噪/嘈杂环境/突发噪声
优秀的抗噪能力-无惧风噪/嘈杂环境/突发噪声风噪:跑步、骑行、车载 嘈杂场景:地铁、酒吧、公交车、十字路口;突发噪声:汽车鸣笛、地铁开关门。
 线性滤波与神经网络相结合的回声消除
线性滤波与神经网络相结合的回声消除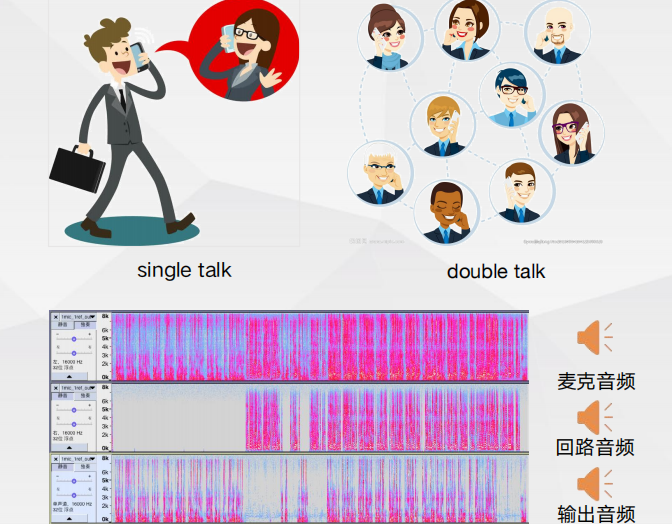 系统的3GPP客观测试方法
系统的3GPP客观测试方法 完整的端到端测试保障主观听感和稳定性
完整的端到端测试保障主观听感和稳定性遍历所有的情况进行端到端测试并保存通话音频,将最终的音频上传至评测平台进行测试,保证用户的体验。
 自研Mockup支撑硬件结构一体化设计
自研Mockup支撑硬件结构一体化设计评估与验证:对市面上的主流耳机进行定向测试、拆解,分析优劣势场景与设计初衷;自研mockup覆盖不同间距、不同防尘网、不同开孔方向、不同形状等;验证不同硬件与结构设计对算法的影响,完善参考设计并定向进行算法优化。
 硬件结构设计对算法的影响模拟评估
硬件结构设计对算法的影响模拟评估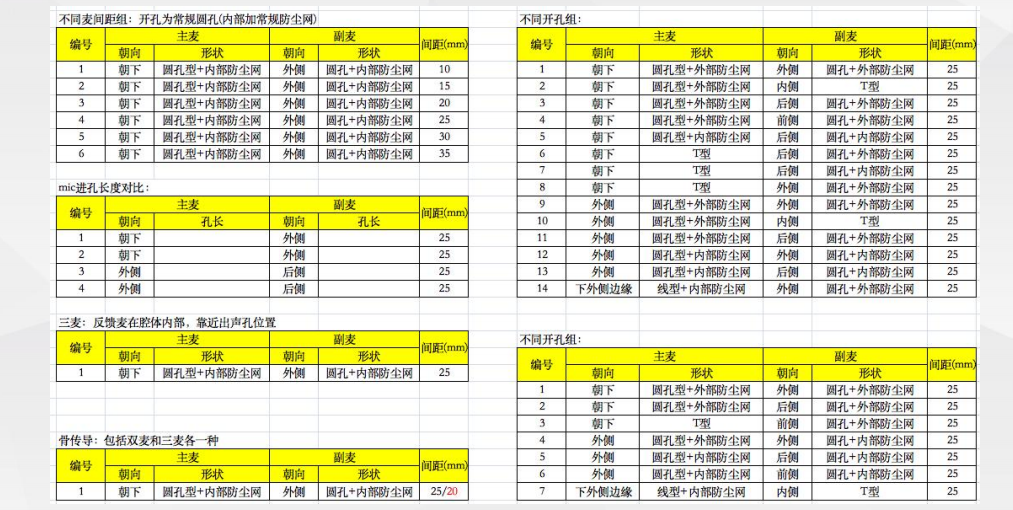 不同骨导元器件对比
不同骨导元器件对比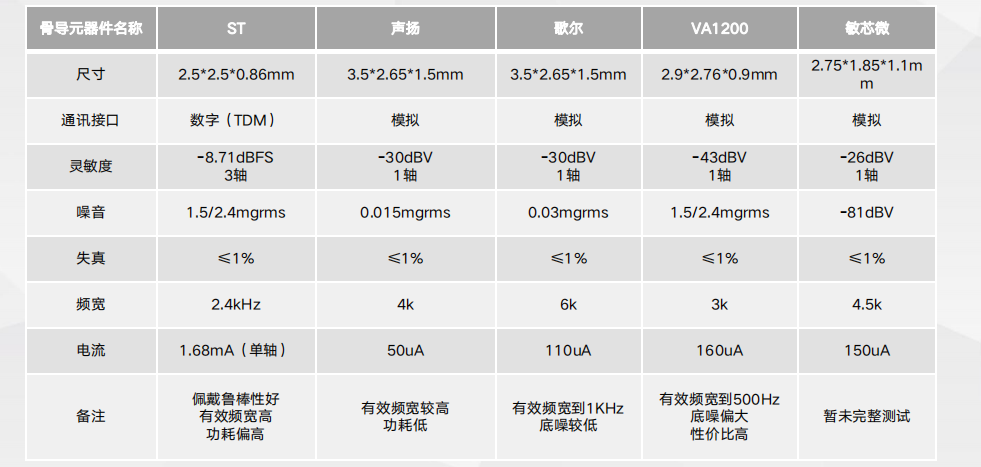 通话降噪-方案优势智能场景检测—助力场景智
通话降噪-方案优势智能场景检测—助力场景智
|
场景
|
具体场景
|
延时要求
|
|
偏安静
|
安静的家居、安静的图书馆、安静的健身房
|
响应时间为3s,恢复时间
为4s
|
|
中等噪声
|
嘈杂的会议室、办公室
|
响应时间为3s,恢复时间
为4s
|
|
重度噪声
|
火车运行时、高峰期城市街道,高峰期购物中心
|
响应时间为3s,恢复时间
为4s
|
|
风噪
|
弱风噪
|
风噪响应为3s以内,强风
噪切换到弱风噪/无风状态
在8s左右响应
|
| 风噪 |
强风噪
|
风噪响应为3s以内,强风
噪切换到弱风噪/无风状态
在8s左右响应
|
|
具体场景
|
地铁场景/非地铁场景、机场场景/非机场场景等
|
|
场景
|
具体场景
|
准确率
|
|
偏安静
|
安静的办公室、安静的家居、安静的会议室、安静的健身房
|
95%
|
|
中等噪声
|
高峰期的餐厅、咖啡厅
|
95%
|
|
重度噪声
|
高峰期的地铁站(内)、高铁站、公交车站
|
95%
|
|
风噪
|
骑行
|
98%
|
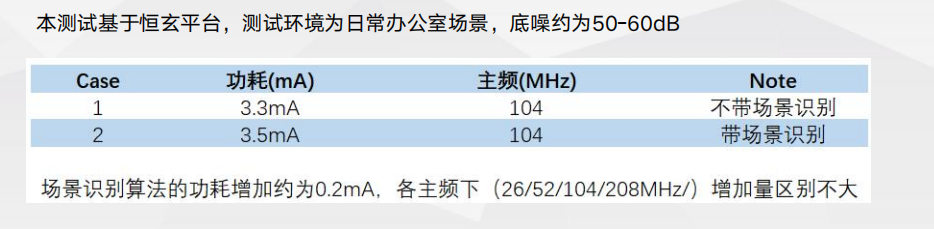
噪声场景检测实测数据本测试基于恒玄平台,测试环境为日常办公室场景,底噪约为50-60dB。
 助听与辅听—自主验配
助听与辅听—自主验配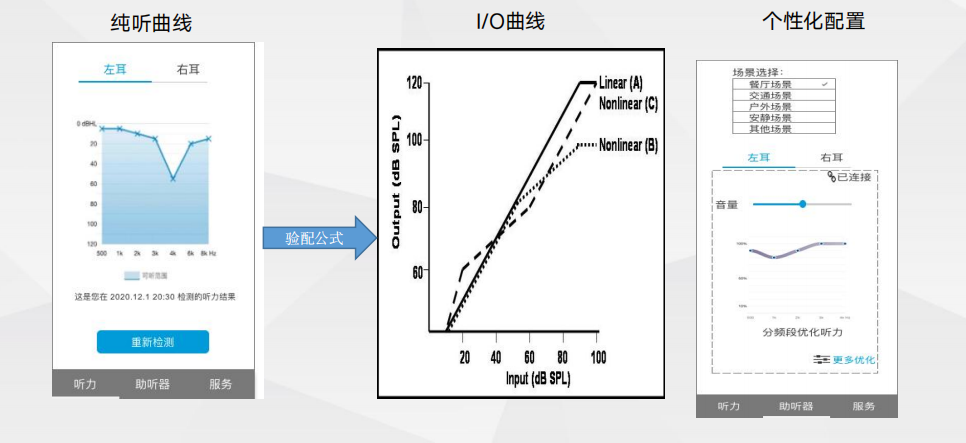 助听与辅听—三大核心算法
助听与辅听—三大核心算法 低功耗离线语音交互链路
低功耗离线语音交互链路 低功耗语音唤醒—— 一声轻唤,享你所想
低功耗语音唤醒—— 一声轻唤,享你所想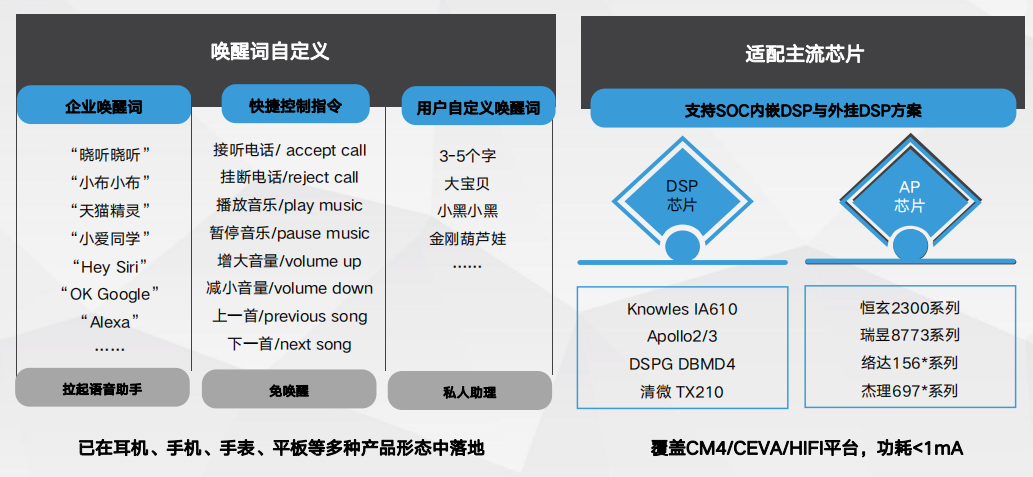 结合骨导信号降低他人误唤醒
结合骨导信号降低他人误唤醒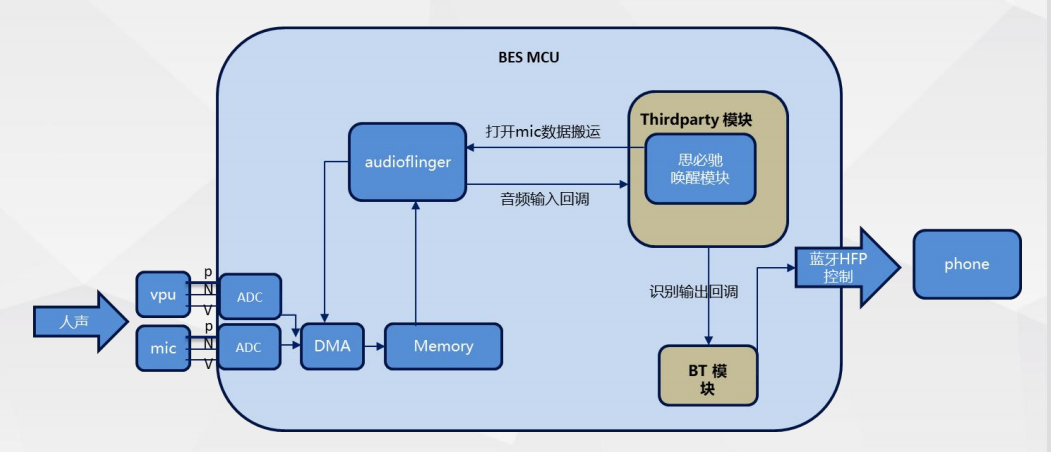 低功耗语音唤醒-唤醒率测试数据
低功耗语音唤醒-唤醒率测试数据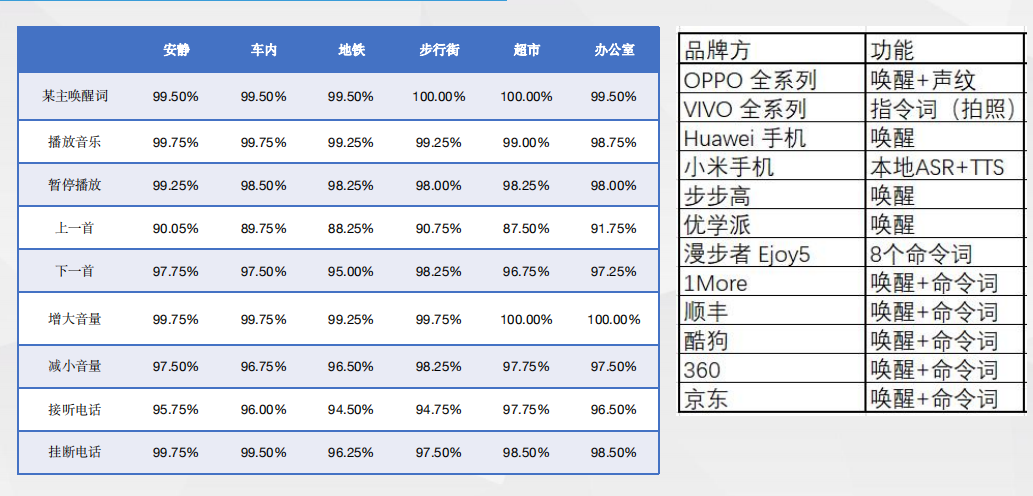 低功耗语音唤醒-唤醒率测试数据
低功耗语音唤醒-唤醒率测试数据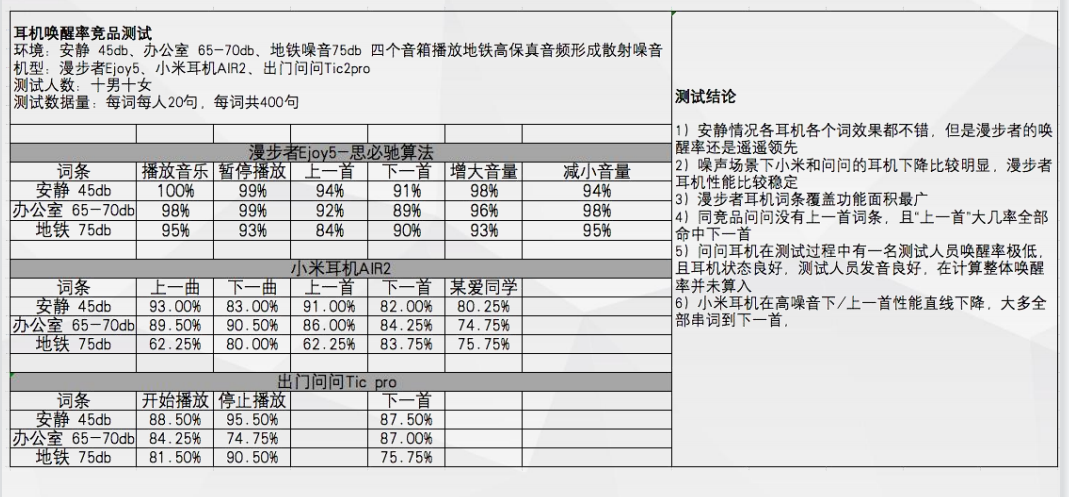 低功耗语音唤醒-方案优势与竞品对比离线多命令词控制 —“你尽管说”
低功耗语音唤醒-方案优势与竞品对比离线多命令词控制 —“你尽管说”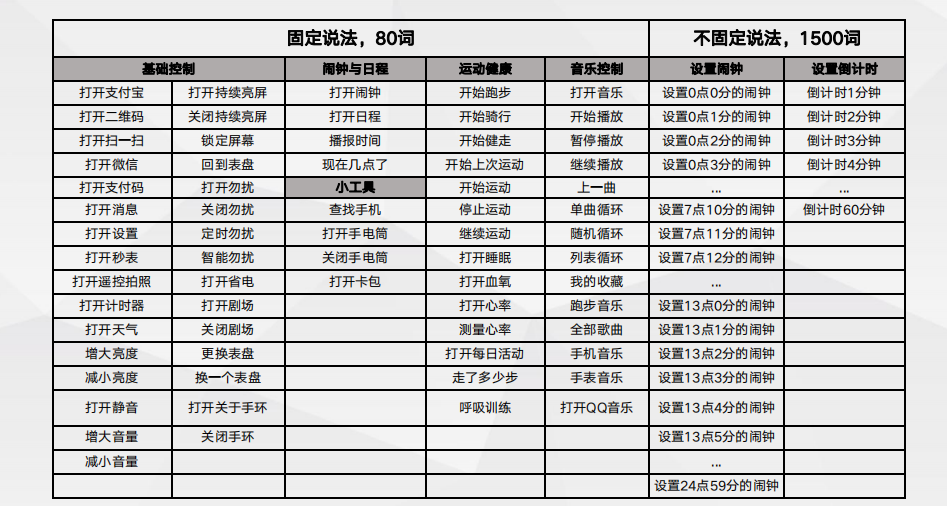 离线多命令词控制 — 低资源占用,性能优秀
离线多命令词控制 — 低资源占用,性能优秀Apollo3平台实测数据: 备注:1580词,固定说法80词+不固定说法 设置闹钟 1440词+不固定说法 倒计时 60词 • 资源占用:RAM 55KB、Flash 160KB、算力45M • 误识别率:所有词一直启用的情况下,18h 10次 • 功耗:一直启用的情况下,1.14mA@5V。
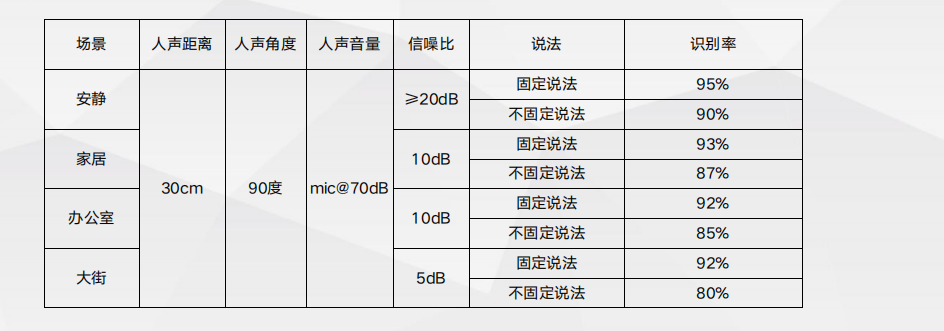 离线多命令词控制 - 主要优势
离线多命令词控制 - 主要优势 离线语音播报-主要优势
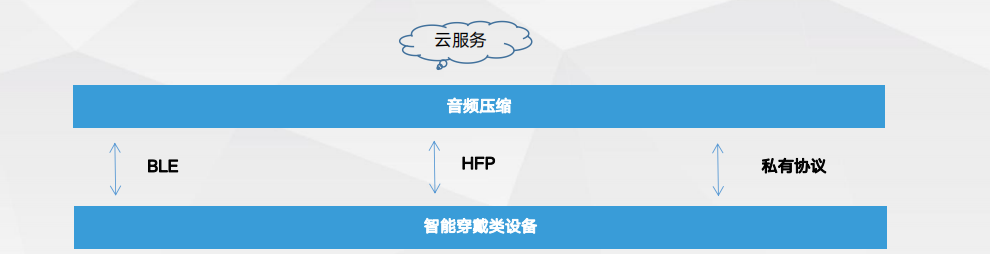
离线语音播报-主要优势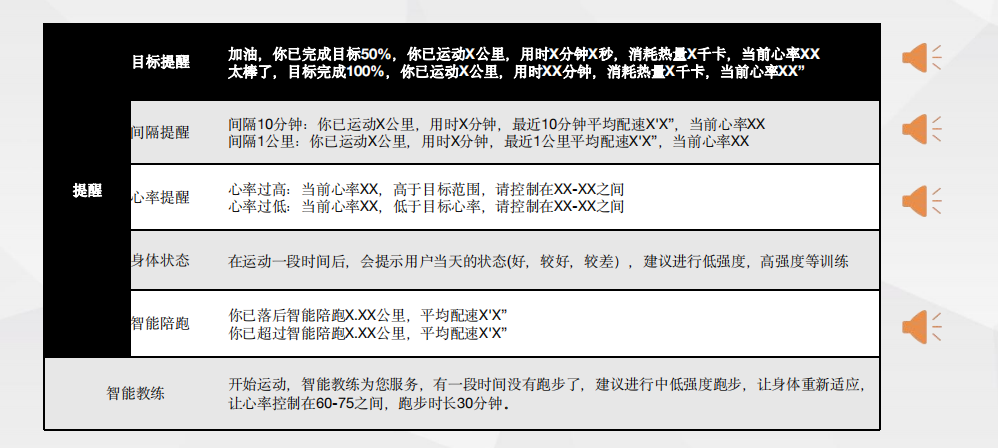 云端能力扩展—助力穿戴设备成贴心秘书
云端能力扩展—助力穿戴设备成贴心秘书实时转写:速度快,准确率高,支持支持2~6个说话人分离语音速记:支持天津、山东、东北、湖北、福建、河北、贵州、陕西等地口音多语种:支持普通话、英语、中英混说、粤语、四川话和上海话翻译:支持中英、英中等主流语钟文本翻译 极速出稿:支持录音文件转写,录音1小时、5分钟出稿 同声传译:普通话语音输入、翻译文本输出。
 典型案例——耳机&手表
典型案例——耳机&手表 典型案例—平板通话降噪
典型案例—平板通话降噪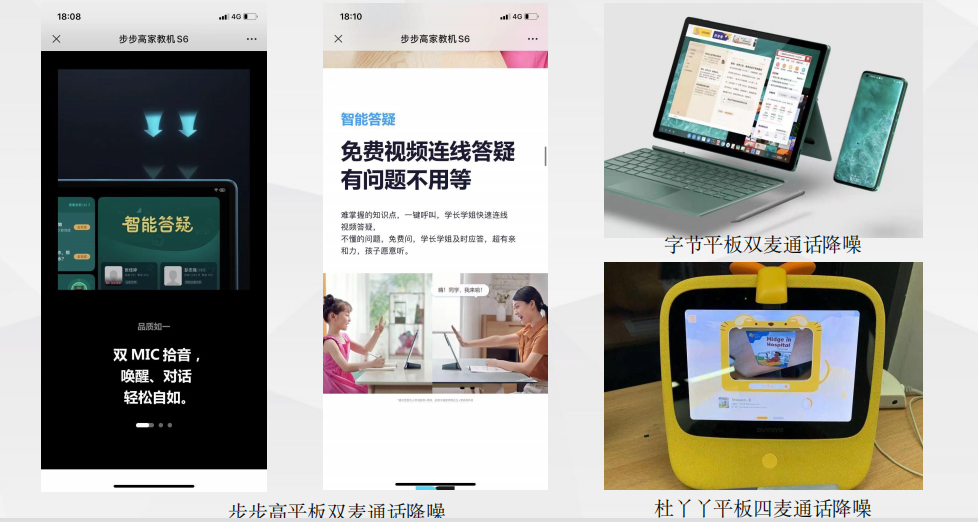 典型案例——MR/CT通话降噪
典型案例——MR/CT通话降噪 典型案例-PC上行通话降噪+下行降噪+唤醒降噪
典型案例-PC上行通话降噪+下行降噪+唤醒降噪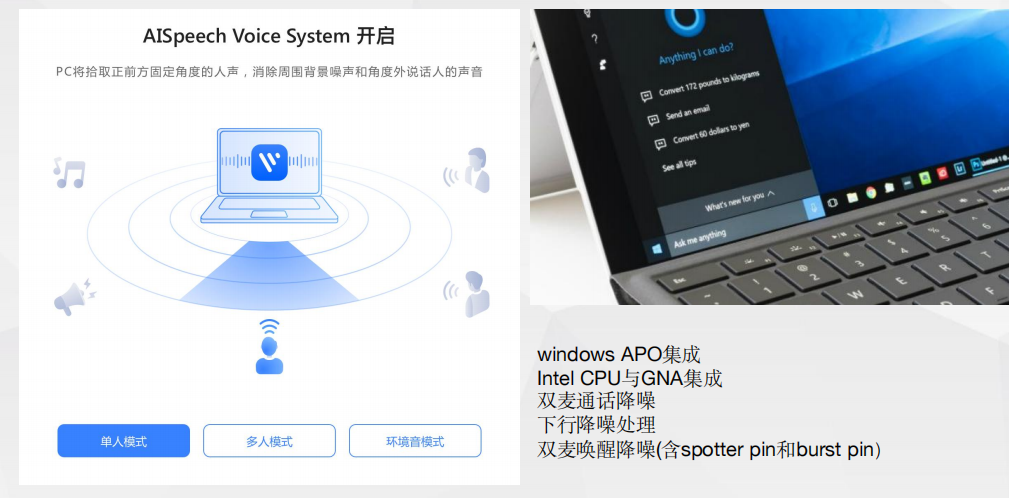 端到端对接流程
端到端对接流程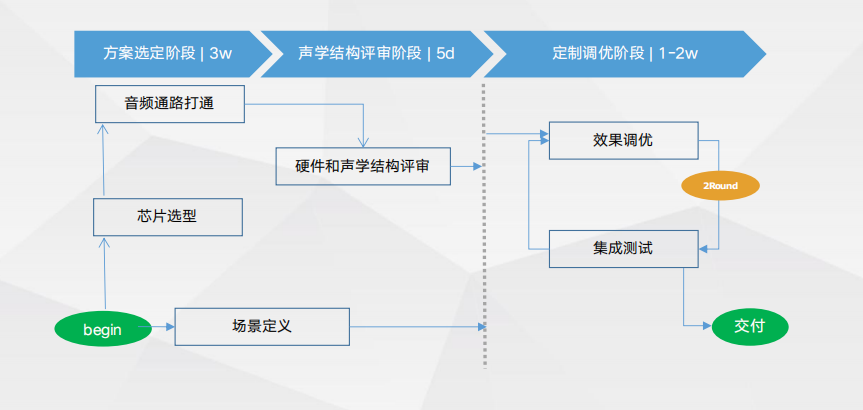
思必驰无线领夹麦解决方案成熟的声学结构设计指导说明,声学腔体仿真验证、丰富麦克风选型推荐和厂商,力求在产品前期ID设计阶段便可得到最佳腔体,节约您的人力、物力 & 时间成本,同时保证产品feature算法的最优化,深化产品的竞争力!
高集成度&有竞争力成本
完善的声学指导建议和配合
通话降噪
稳定传输低延时
思必驰手机音频解决方案可以盲人/聋哑人应用、智能场景识别、自定义唤醒、语音解锁密码、与可穿戴设备联动、全双工人机对话、语音转文本、方言与翻译、语音+图像识物,以及不再拘束于唤醒词,提供更自然的语音交互能力。在我们的日常生活中,不会和别人说话时每说一句话就叫对方名字一次,全局生效或者在应用内生效,如拍照摄影、游戏控制、音乐播控。
低功耗唤醒与多级校验
自定义唤醒
免唤醒命令控制
场景识别与声音事件检测
思必驰智慧物联解决方案基于海量声学和文本数据,提供以任务型对话为主,兼具闲聊和问答的综合性对话服务。提供通用的内置技能;支持自定义对话逻辑和内容;细致到每一轮交互的超高度定制。
全链路对话
超高度定制
语音输入板
声纹识别













领先的企业数字化服务平台
客服电话:400-0972-788

