
 “六大”核心技术
“六大”核心技术基于优秀的基础核心能力,构建智能化的图像采集方案,实现自动化的业务流程
深度学习OCR引擎 核心技术:印刷体&手写体识别
核心技术:印刷体&手写体识别 印章、签名检测识别
印章、签名检测识别 核心技术:复杂表格检测
核心技术:复杂表格检测 图像处理\检测技术
图像处理\检测技术 核心技术:图像、文档分类
核心技术:图像、文档分类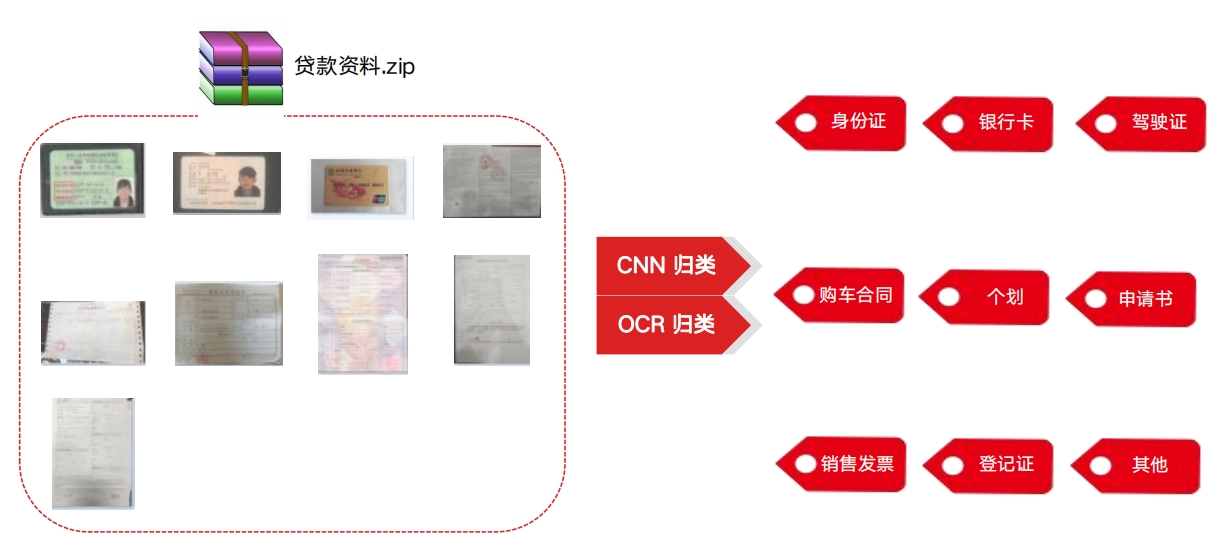 核心技术:移动端(深度学习SDK)
核心技术:移动端(深度学习SDK)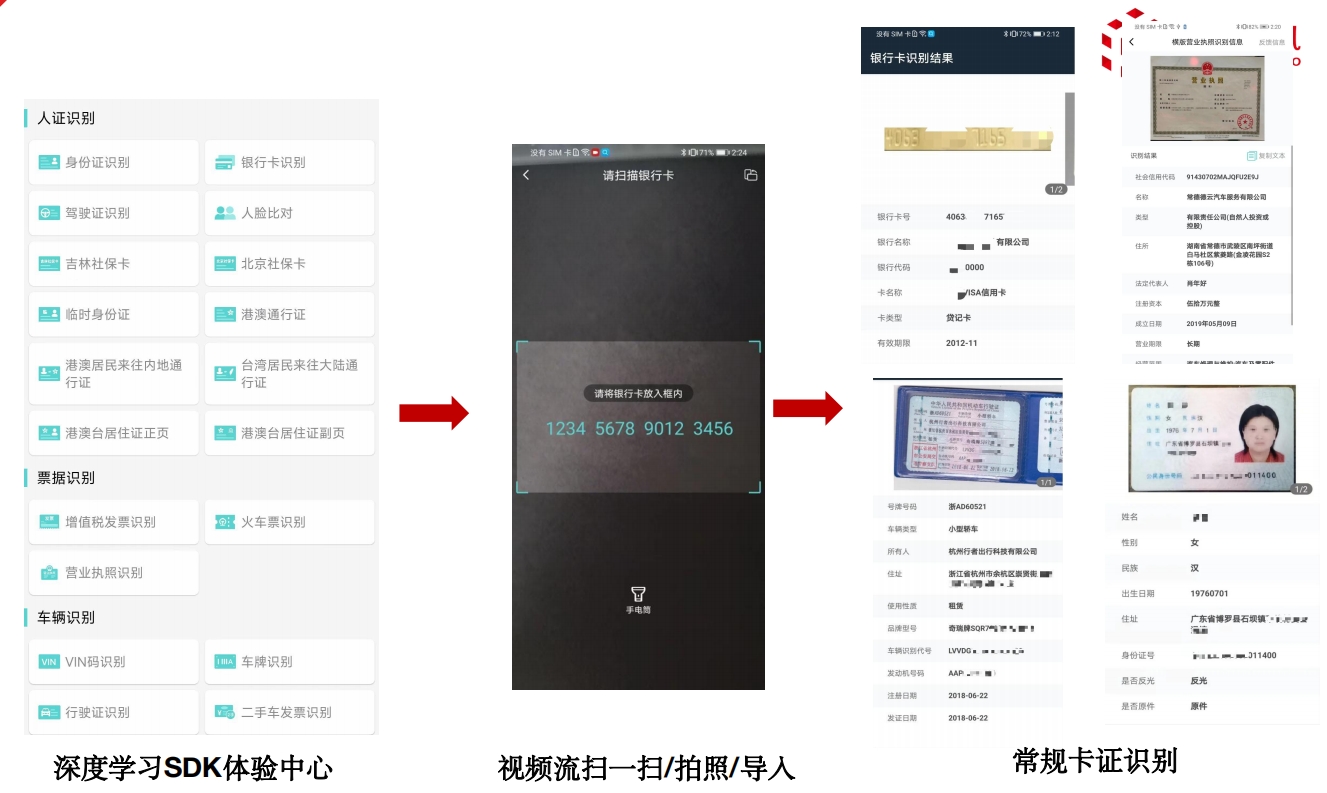 NLP智能分析
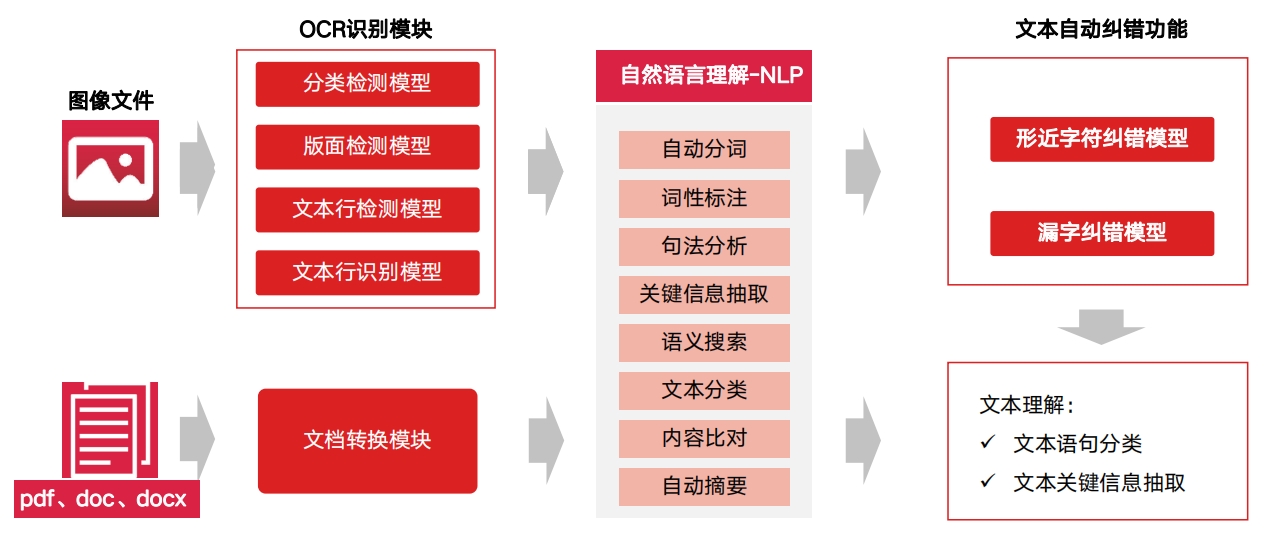
NLP智能分析基于深度学习的OCR技术配合文本自动纠错功能,融合上下文语义技术,自动完成纠错和填充,提升识别精度。可以处理图像、PDF、DOC、DOCX多种格式的文档
我们的技术优势译图智讯产品矩阵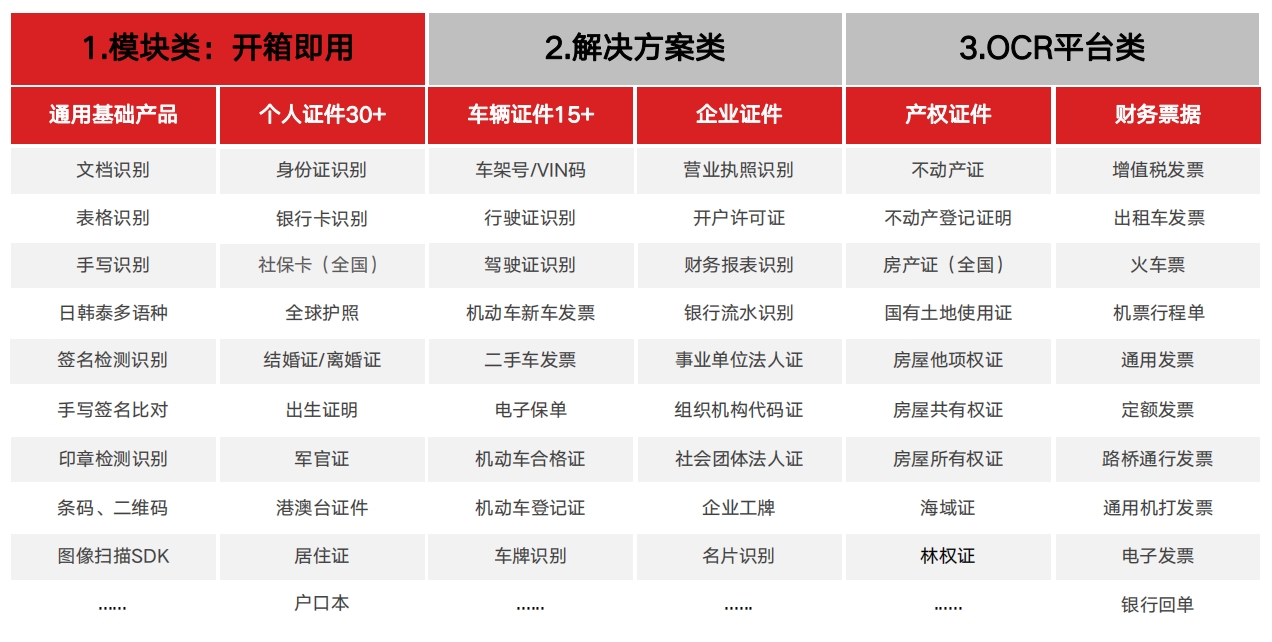 通用文档OCR识别
通用文档OCR识别 证照识别
证照识别 房产证识别 — 支持全国范围
房产证识别 — 支持全国范围识别覆盖全国所有省市版式,自动区分版式,无需手动选择,支持多格式识别,支持手机拍照图、扫描图、复印件的识别
 财务票据识别
财务票据识别 产品矩阵合同比对方案-处理流程
产品矩阵合同比对方案-处理流程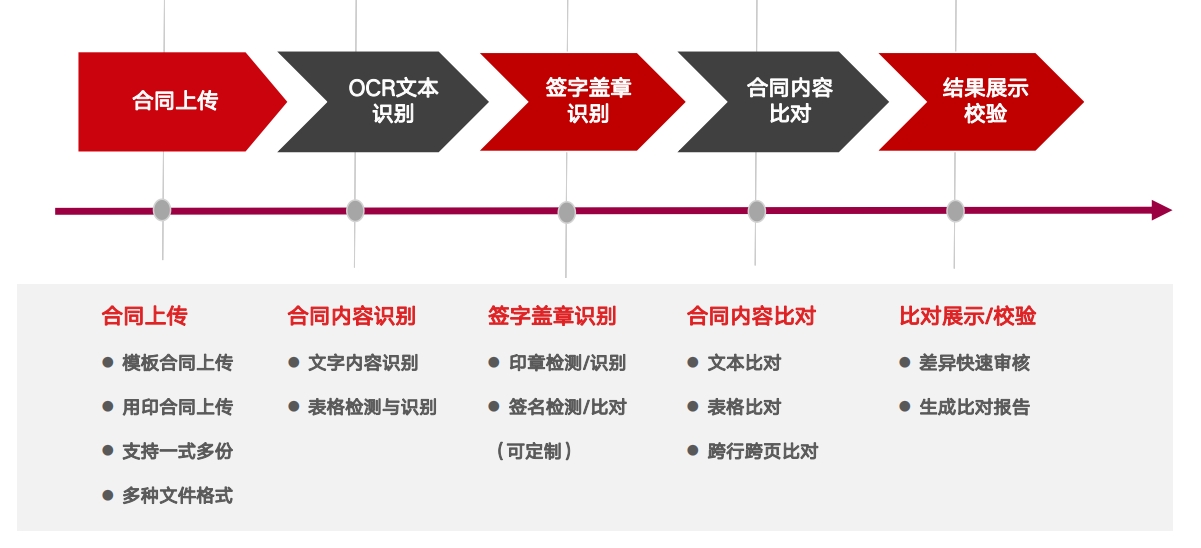 合同智能比对
合同智能比对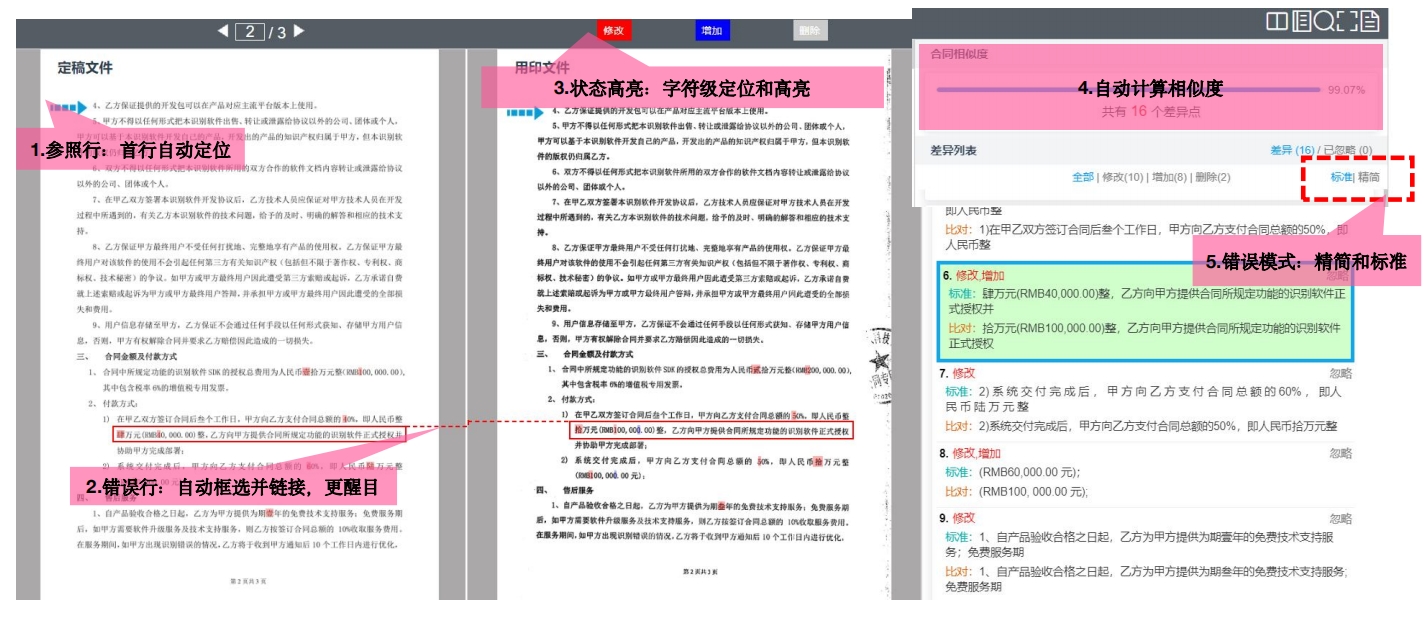 文本智能提取训练平台
文本智能提取训练平台文本智能提取系统为用户提供强大、灵活的的文本信息提取能力,可实现批量的、自动化的提取,可以大幅提升信息处理效率,辅助业务人员获取录入关键信息,降低人工疏漏带来的风险。用户可以灵活的定义合同提取模型,系统具备标注、训练学习的能力,快速实现模型生成和迭代。
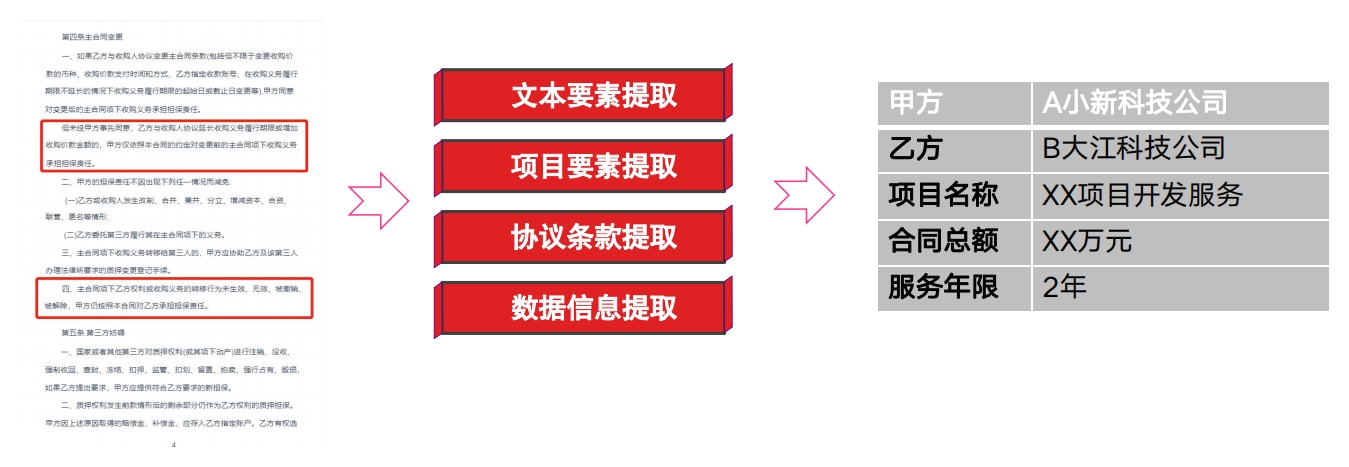
文本智能提取训练平台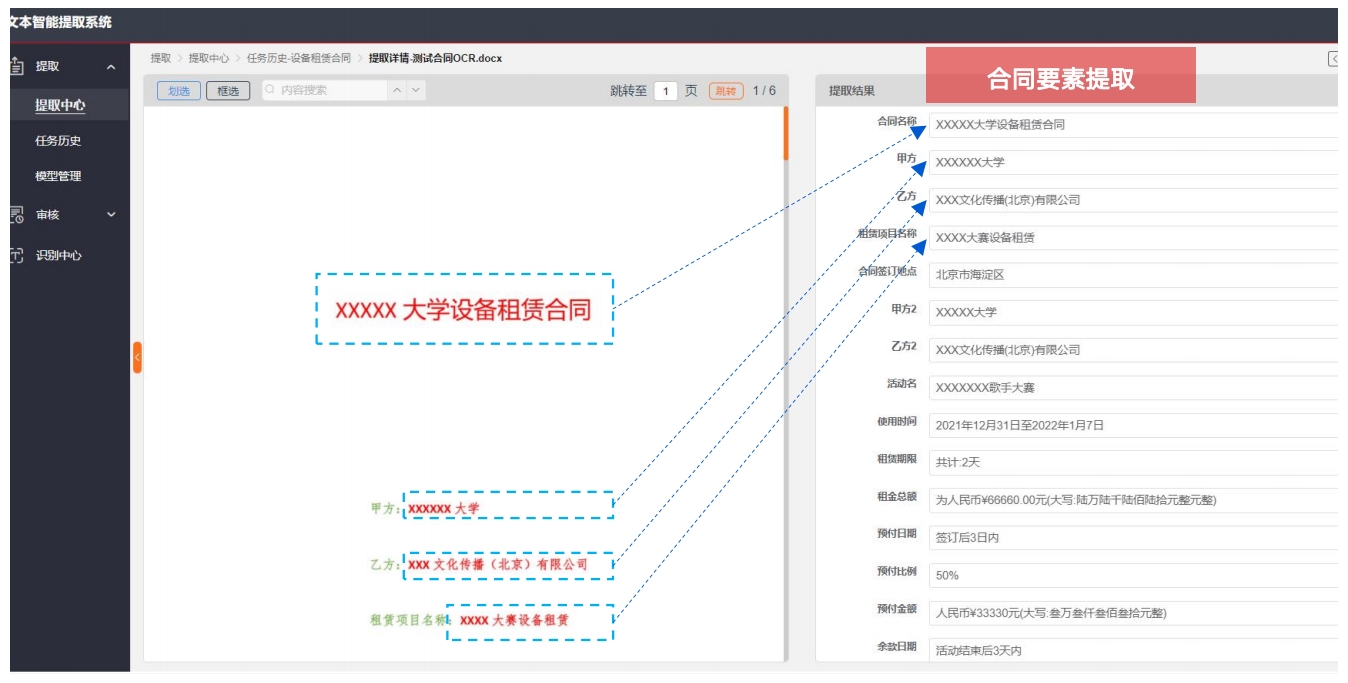 文本智能提取训练平台
文本智能提取训练平台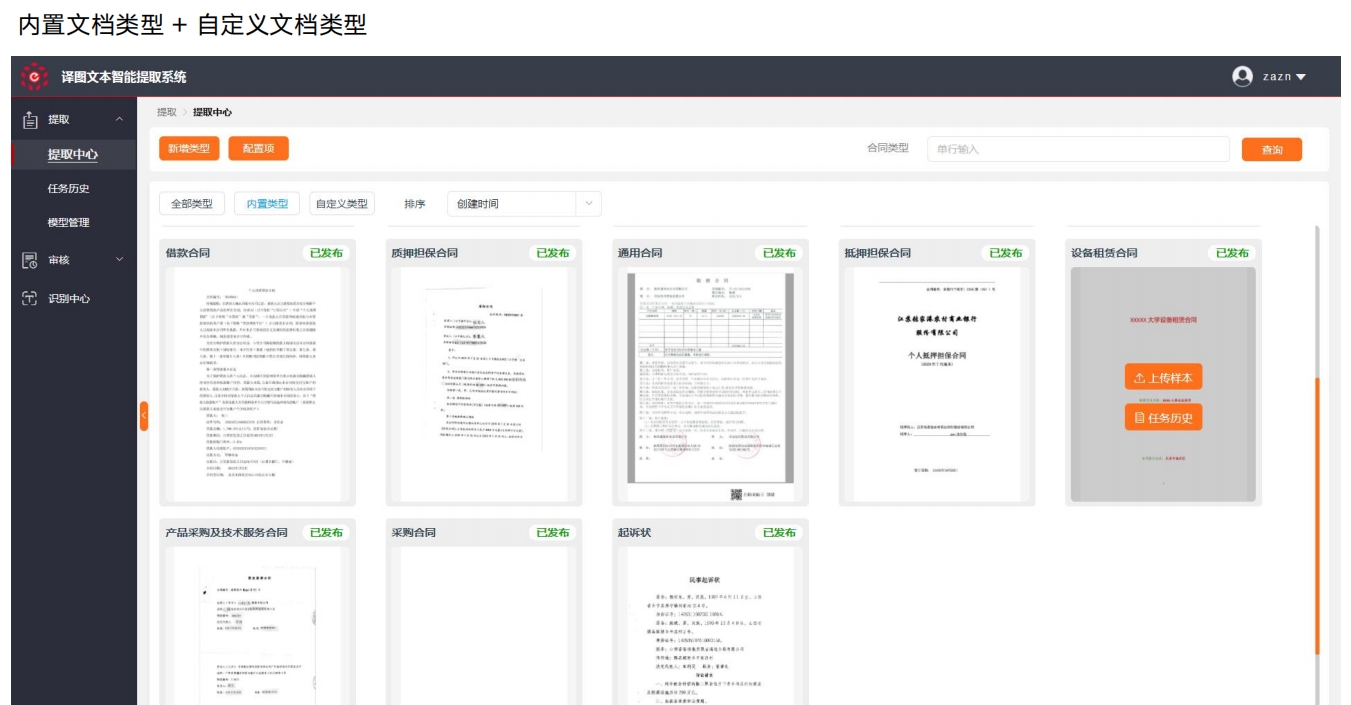 财务报表自动识别
财务报表自动识别财报识别解决方案核心能力:基于AI能力的OCR识别引擎,解决低分辨率下文字识别率低的问题;预置科目匹配词典,自动匹配纠正描述不一致的科目达到数据规范统一;预置科目平衡校验公式,自动进行项目的勾稽计算,实时提示配平;灵活定义输出模板,按照用户自定义输出模板导出报表数据。

财务报表自动识别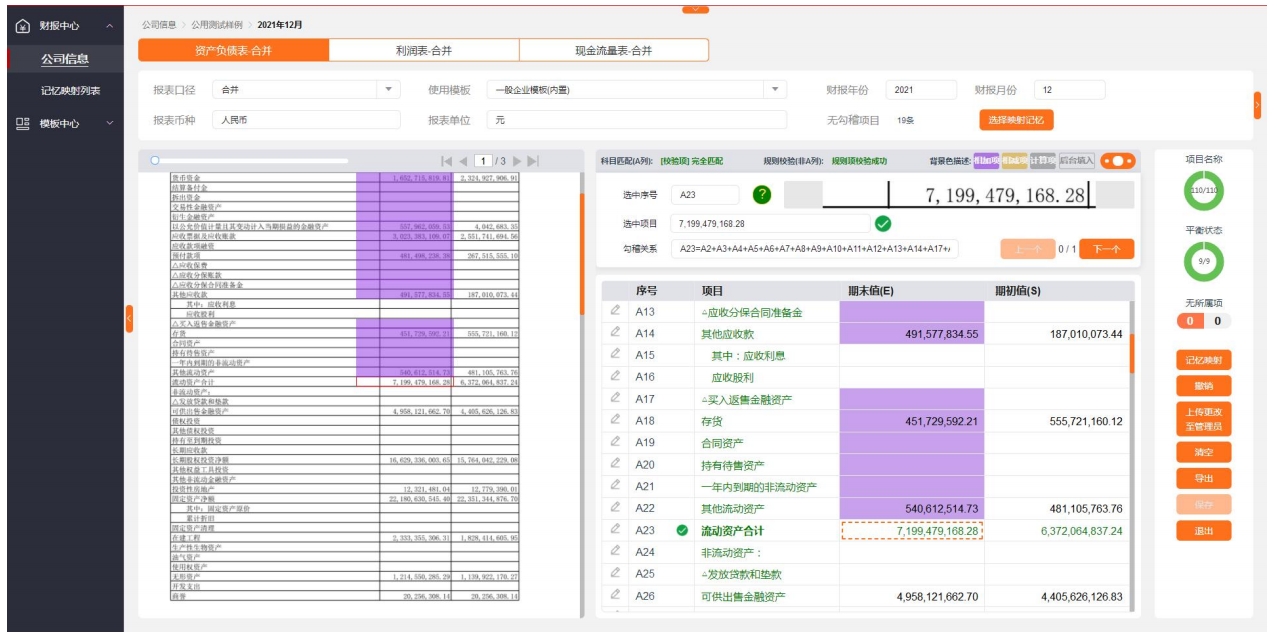 财务报表—产品功能
财务报表—产品功能 信贷审核:银行流水自动录入审核
信贷审核:银行流水自动录入审核 译图智讯银行流水识别产品
译图智讯银行流水识别产品 银行对账单版式现状
银行对账单版式现状 译图智讯银行流水识别解决方案-核心功能特性
译图智讯银行流水识别解决方案-核心功能特性 译图智讯产品矩阵OCR识别管理平台
译图智讯产品矩阵OCR识别管理平台 集成扩展能力
集成扩展能力平台可与公司现有的ESB(企业服务总线)、IAM(统一身份认证)系统进行集成,实现统一身份管理,实现ESB对所有交互接口的统一管理。
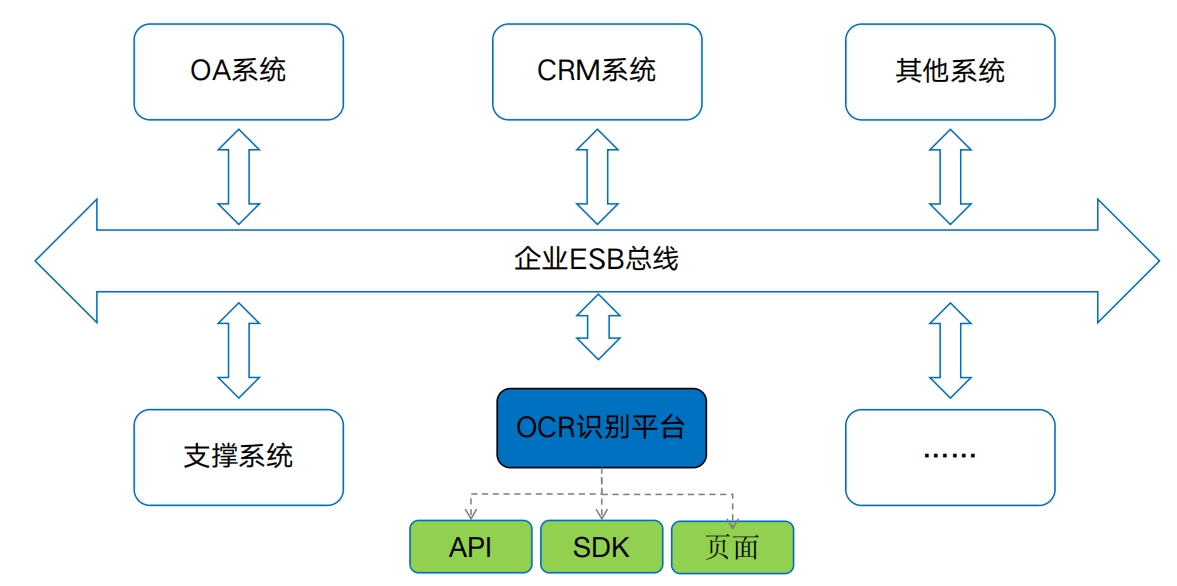
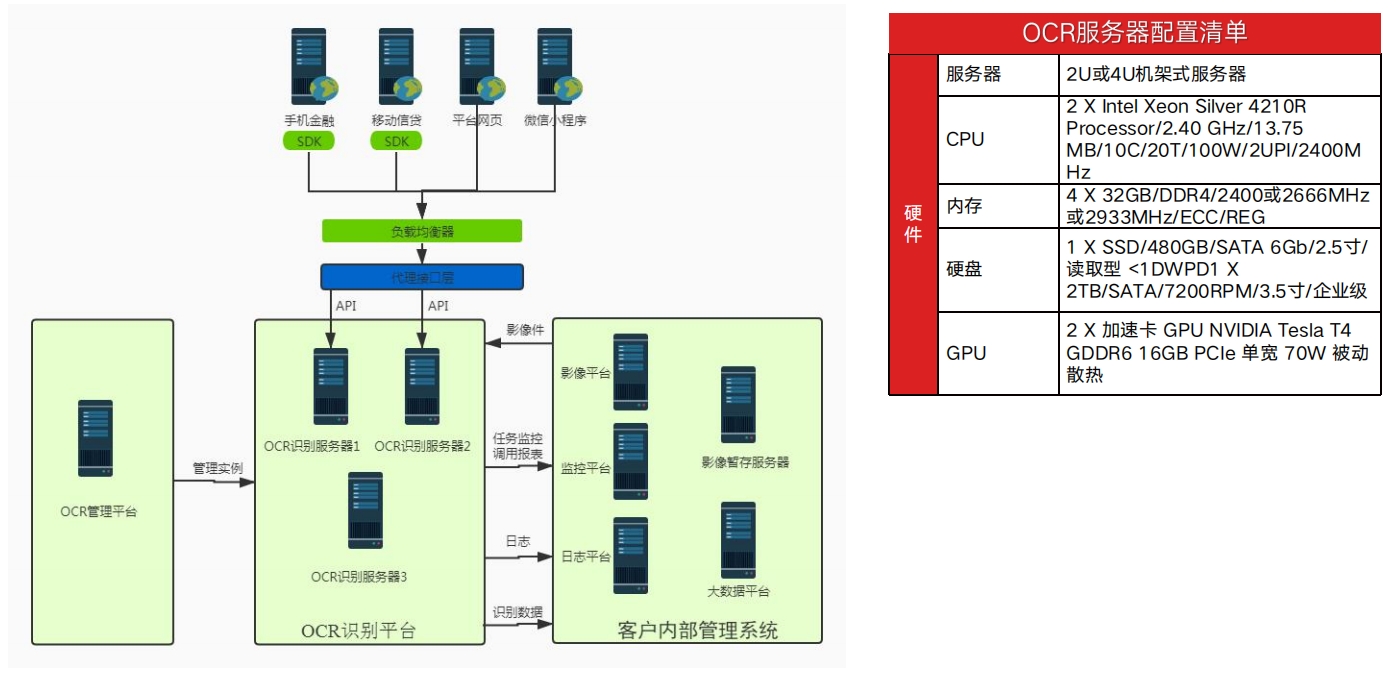
OCR识别平台物理架构我们的优势:全部产品同时支持GPU环境、CPU环境、信创环境的部署,支持Linux、Windows、手机系统;对硬件消耗资源低,可在6G显存环境部署,16G显存至少5并发,同等GPU资源条件并发性能优于同行。
OCR训练平台工作流程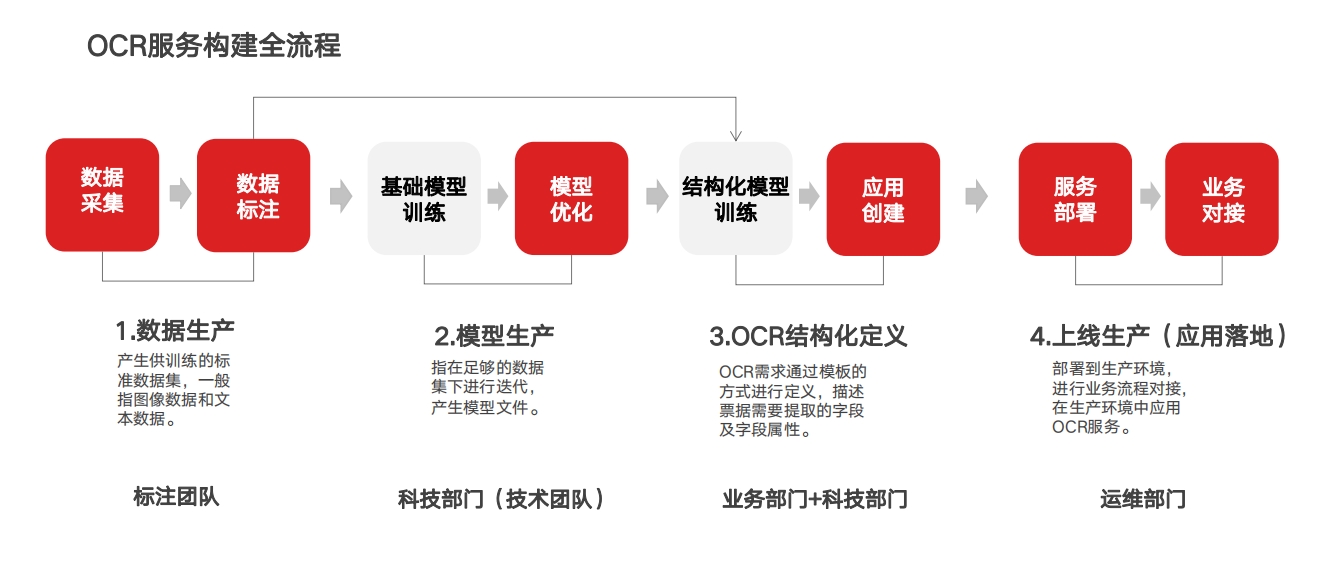 训练平台(演示)
训练平台(演示)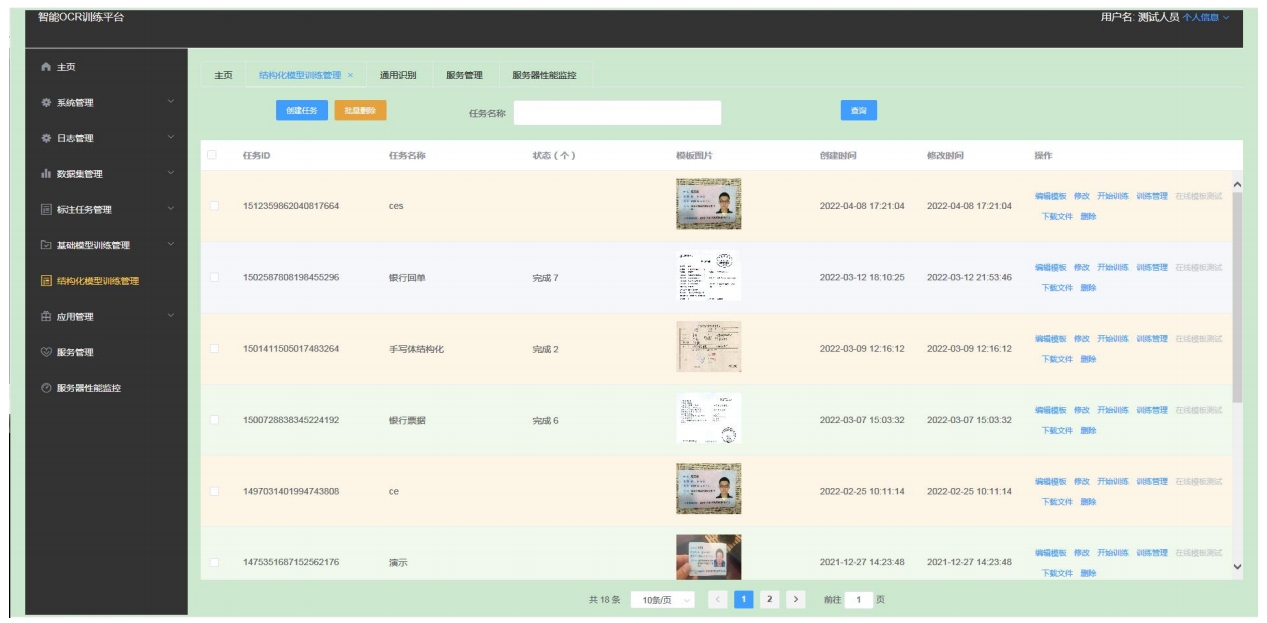 训练平台技术架构
训练平台技术架构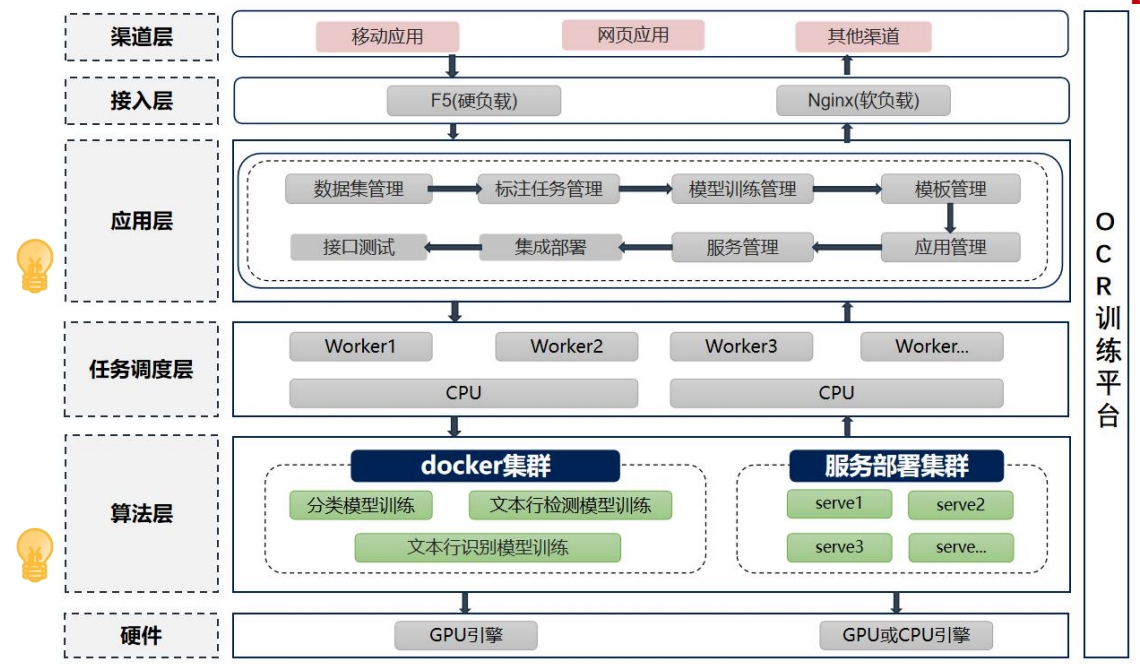 私有化部署
私有化部署独立部署在用户服务器与系统对接,通过内网通信实现数据传输,文档数据均保留在用户私有的服务器上,保证数据安全。
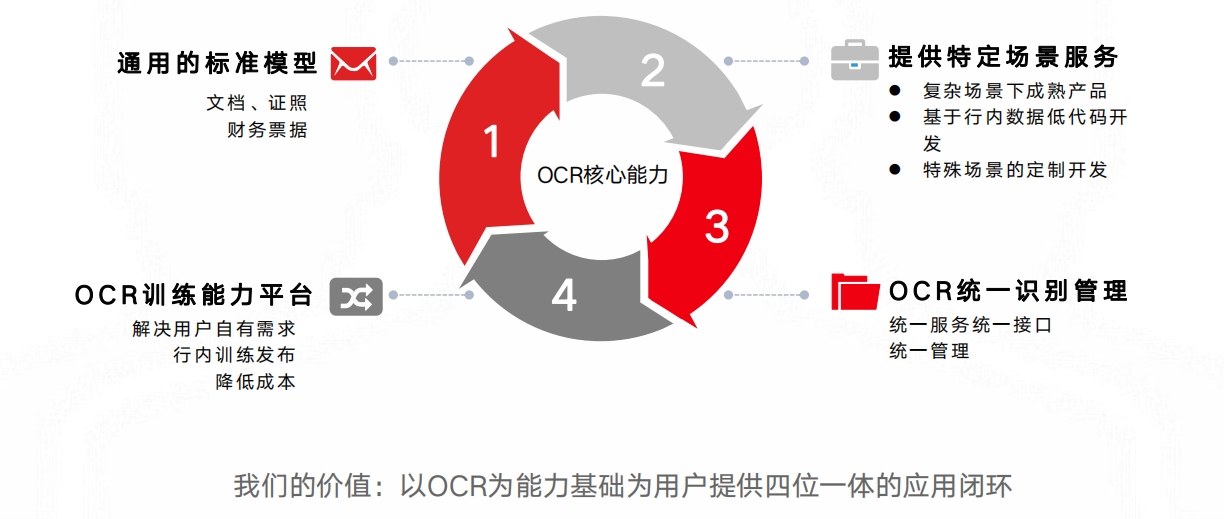
用户目标&我们的价值用户目标:接入统一的OCR识别中台能力,构建金融AI中台
银行解决方案覆盖银行多业务场景下证件、票据、凭证单据的智能化采集,快速自动采集图像上的信息要素,有效代替人工录入和审核工作,降本增效。OCR能力可以部署到银行的AI中台,通过API直接对接到银行业务系统。

开户:证卡识别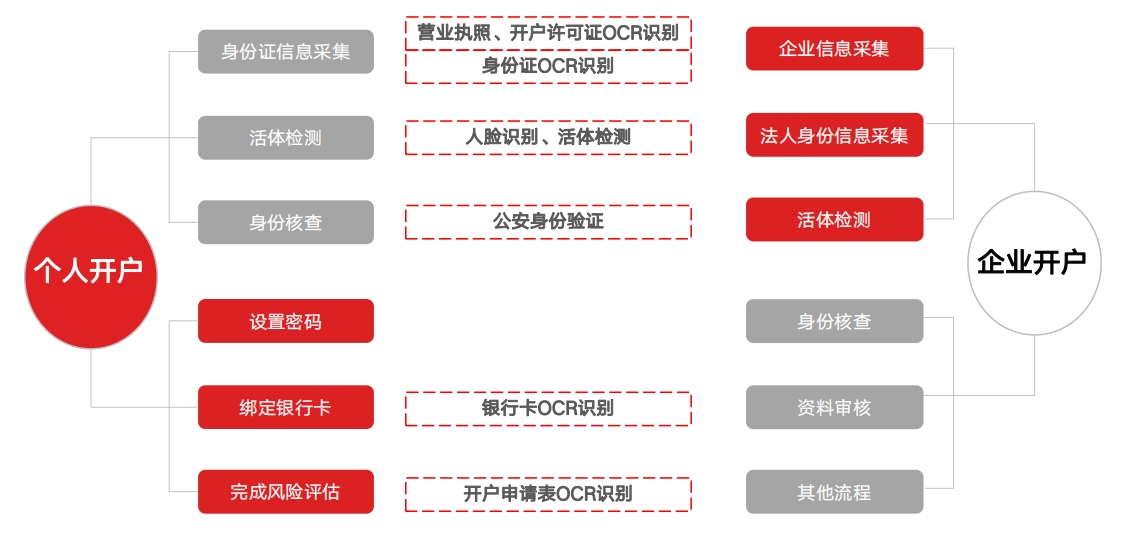 信贷审核:证照自动化录入
信贷审核:证照自动化录入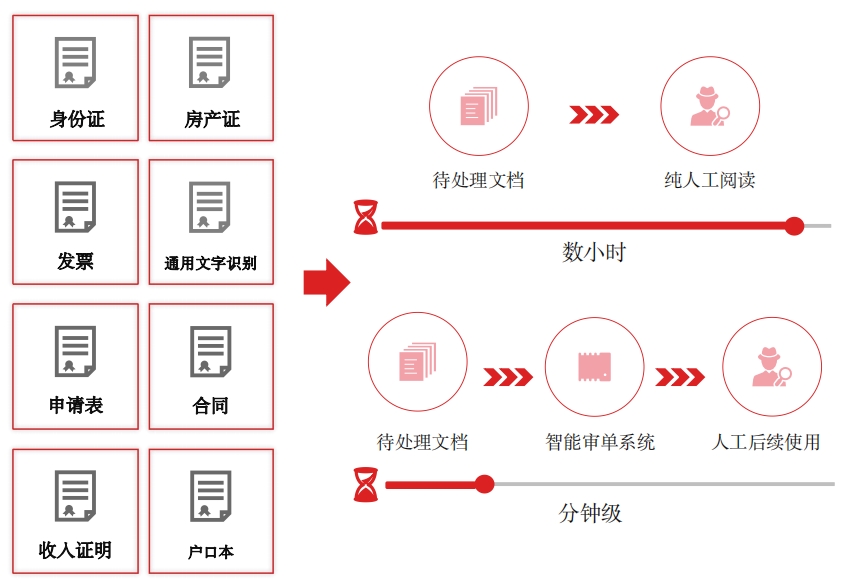 信贷审核:银行流水识别文本智能提取训练平台OCR能力扩展:模型训练及智能结构化
信贷审核:银行流水识别文本智能提取训练平台OCR能力扩展:模型训练及智能结构化 OCR训练平台 从零开始构建OCR服务
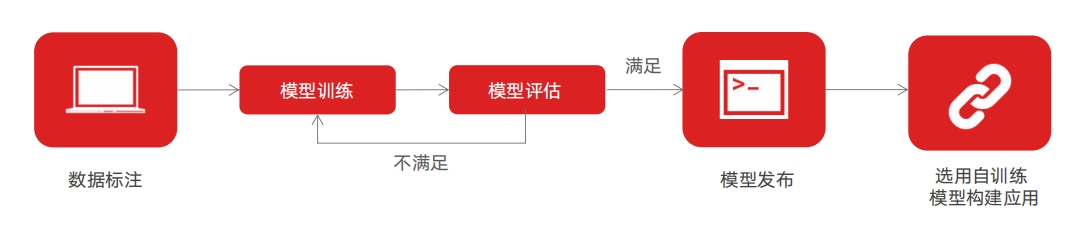
OCR训练平台 从零开始构建OCR服务对于部分场景,可能内置模型达不到要求,比如一些特殊字体的支持等等,需要训练特定的模型以提高识别率,通过训练得到新模型,然后采用新模型构建OCR应用流程。
典型案例 一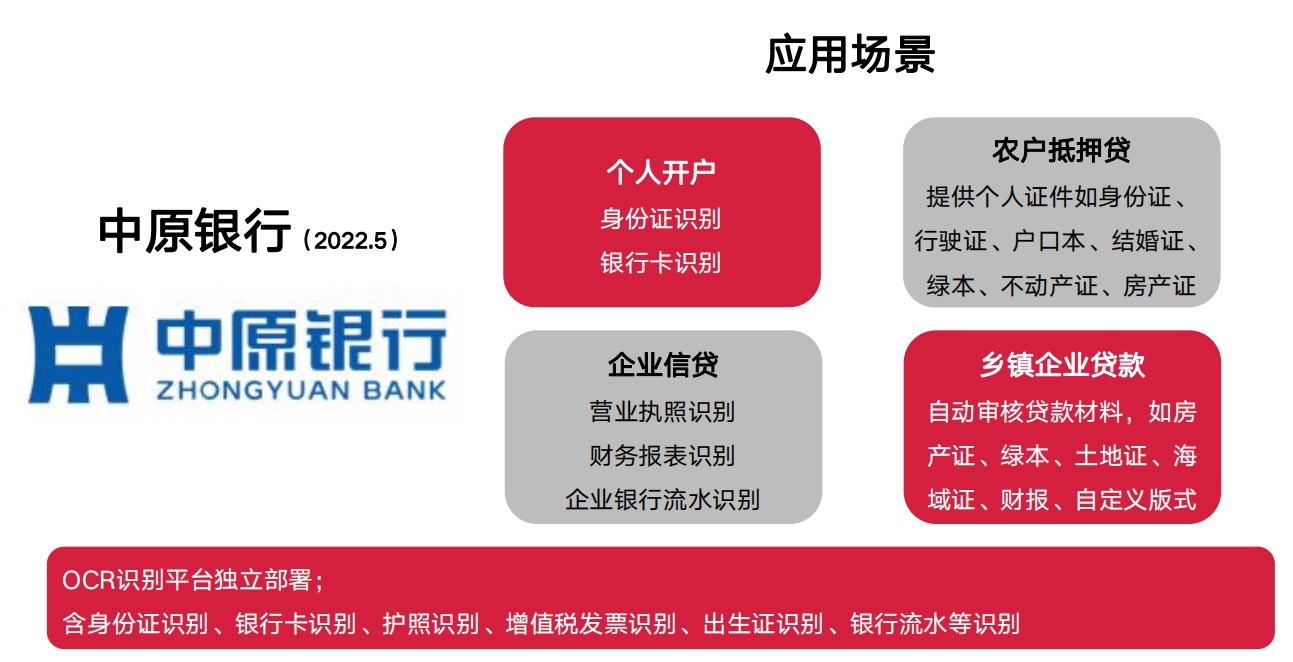 典型案例 二
典型案例 二 银行部分案例
银行部分案例 保险部分案例
保险部分案例 汽车金融部分案例
汽车金融部分案例 企业部分案例
企业部分案例
左手医生病历OCR识别及结构化处理系统基于OCR和自然语言处理技术将门诊/住院病历、检查检验报告、处方/医嘱等医疗文档自动识别、转换为结构化数据 ,支持下游可视化、统计分析、推理等应用,可用于健康档案、质控、保险理赔及临床科研等业务场景。
医疗信息结构化识别
医疗文档自动分类
敏感信息定制化屏蔽
关键信息高亮展示
文本图像增强是基于行业领先的计算机视觉技术,面向文件类图片场景提供图像处理服务。提供切边增强、弯曲矫正、阴影去除、摩尔纹去除、图像提亮等多项功能特性。旨在帮助客户更便捷、更快速地获取清晰度更高、阅读性更强的文档类图片,更好地服务客户后续业务流程。
切边增强
弯曲矫正
阴影去除
摩尔纹去除















领先的企业数字化服务平台
客服电话:400-0972-788

