
 GPU当前现状
GPU当前现状 GPU 共享方案拦截分析
GPU 共享方案拦截分析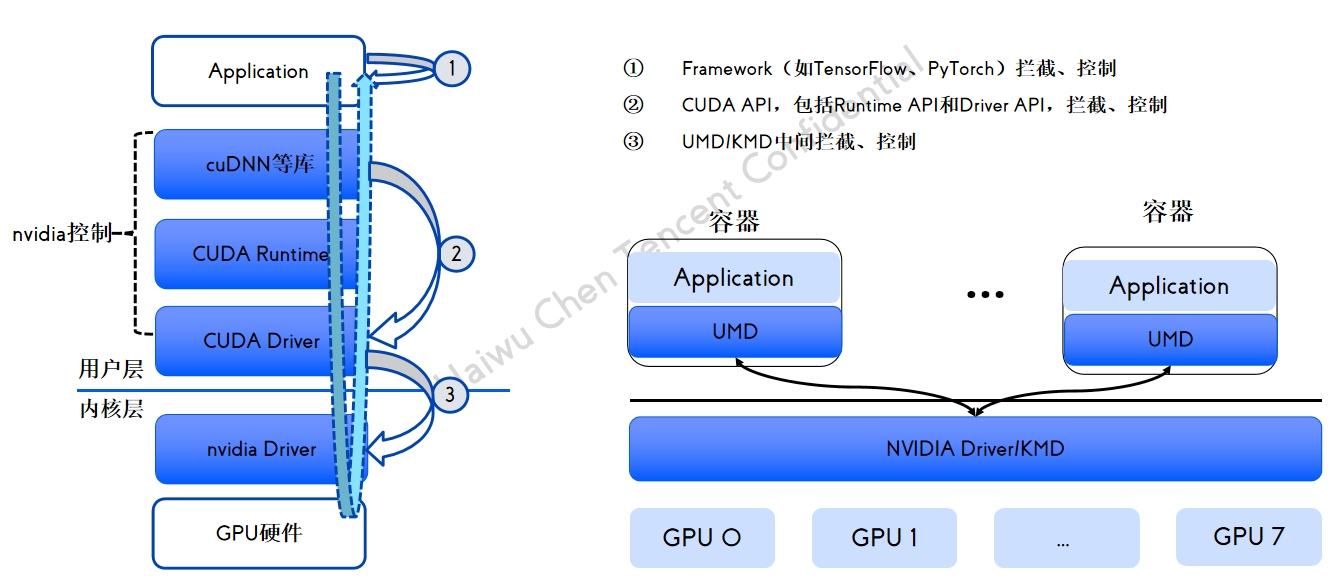 qGPU 容器产品介绍
qGPU 容器产品介绍 qGPU调度策略
qGPU调度策略
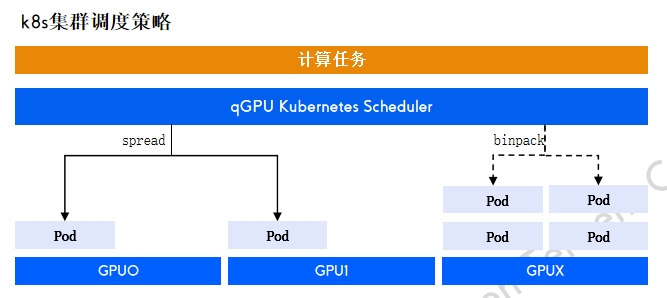 qGPU 单卡调度policy
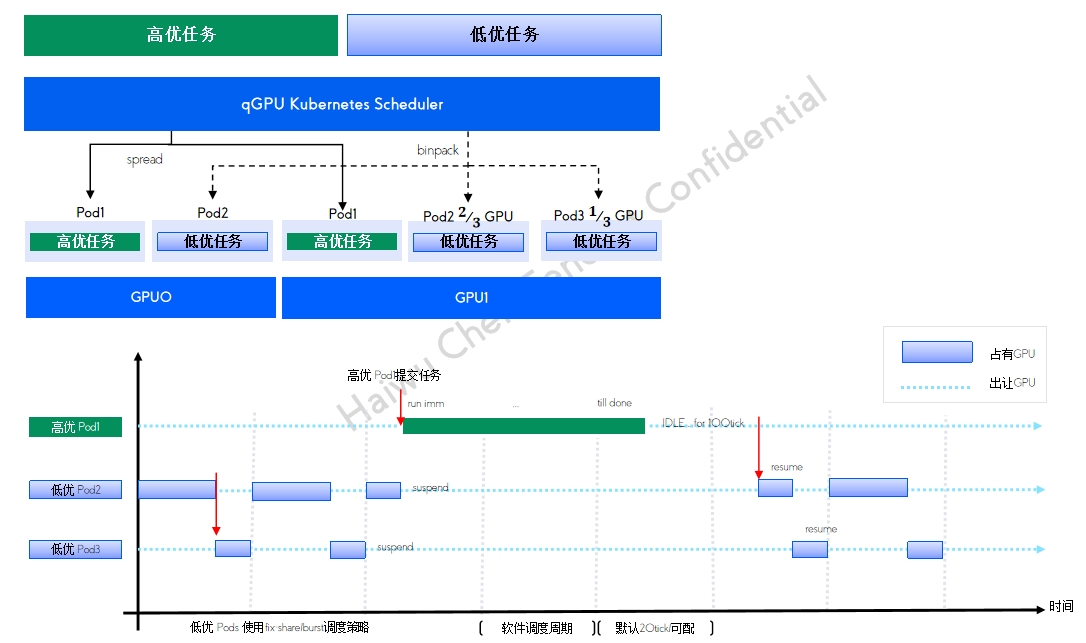
qGPU 单卡调度policy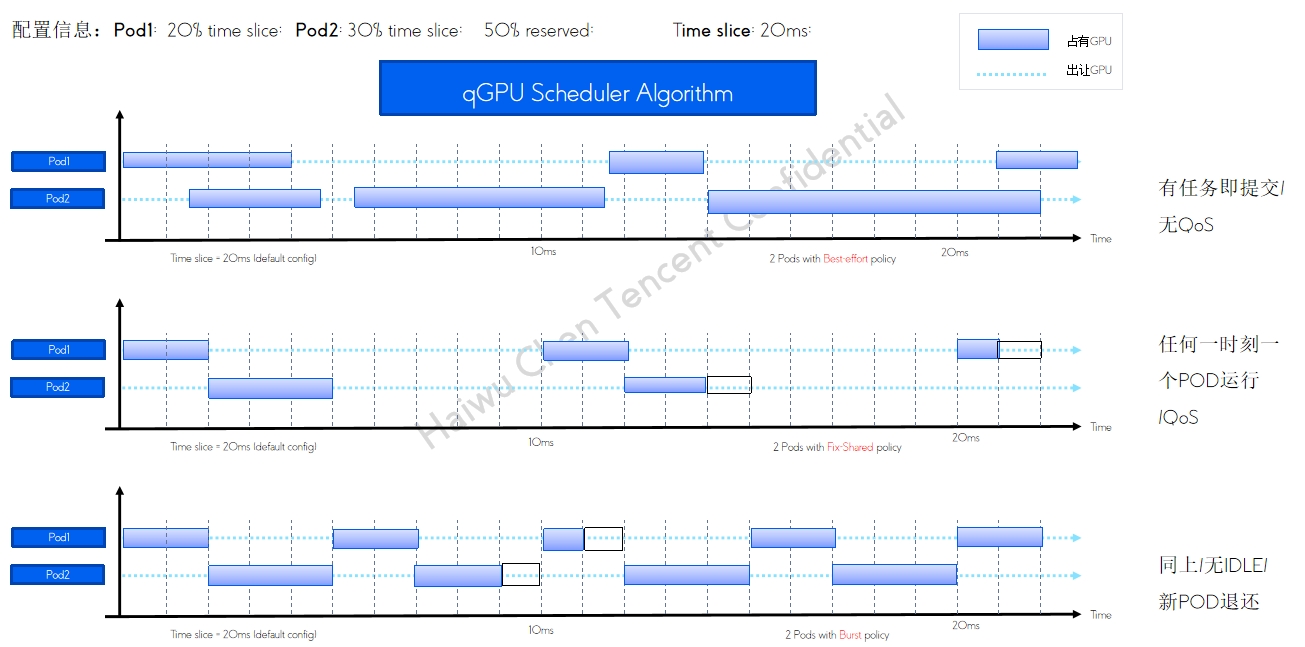 qGPU 在离线混部及调度方式
qGPU 在离线混部及调度方式高优任务 平均分配 保证负载均衡 低优任务 尽量填满 保证资源利用率 支持在线 100% 抢占 GPU利用率的极致提高 业内唯一GPU在离线混部技术
支持主流OS版本 qGPU交付方式
qGPU交付方式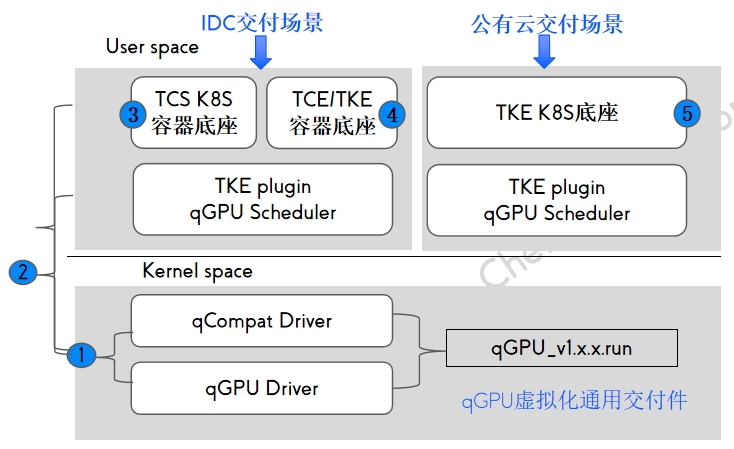 qGPU IDC交付件
qGPU IDC交付件 公有云使用qGPU
公有云使用qGPU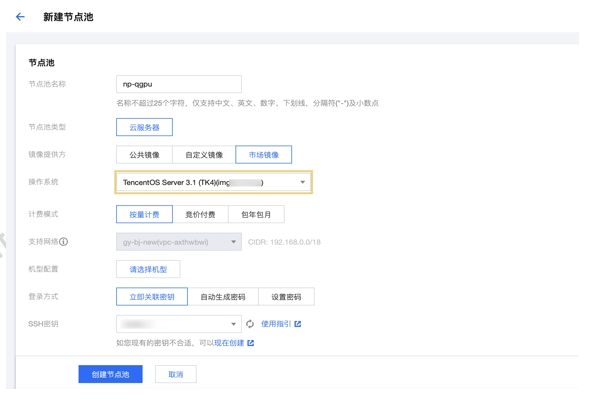 qGPU监控组件elastic-gpu-exporter
qGPU监控组件elastic-gpu-exporter 使用限制案例一:某头部互联网企业OCR场景
使用限制案例一:某头部互联网企业OCR场景 案例二:某在线教育AI推理业务
案例二:某在线教育AI推理业务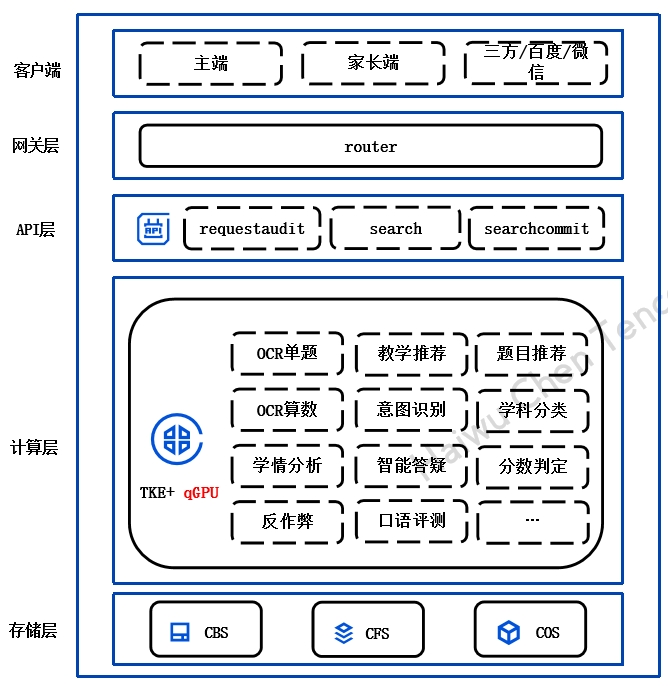
是一个分布式、高吞吐量、高可扩展性的消息系统,100%兼容开源 Kafka API 0.9.0至2.4.2版本。CKafka 基于发布/订阅模式,通过消息解耦,使生产者和消费者异步交互,无需彼此等待。
一个分布式、高吞吐量、高可扩展性的消息系统
100%兼容开源 Kafka API 0.9.0至2.4.2版本
通过消息解耦,使生产者和消费者异步交互,无需彼此等待
腾讯轻联零代码应用集成与数据集成平台,腾讯云iPaaS是一个以腾讯云为技术基座,背靠300+伙伴生态,通过核心的图形化开发界面,专注于系统集成、数据融合、SaaS集成、MQ消息集成、API全生命周期管理的新型云集成服务平台。
系统集成
数据融合
SaaS集成
MQ消息集成
智能公播,是一种搭载音频广播管控软件+公播版权音乐二合一的产品,比如,商场、公园、飞机场、地铁站、或者是行政办公大厅、医院、酒店等,公播音乐是为这些场所提供有版权的背景音乐,同时提供一套集中的管控平台,成为一个独特的声音媒介,实现统一的监管、政策的发布、文化传播、广告宣传等。
超大曲库,版权音乐安心使用
高效系统,集中控制提高效率
语音播报,通知消息有效下发
适配门店,不同场景快速接入
















领先的企业数字化服务平台
客服电话:400-0972-788

