






阿里云数据总线DataHub
立即咨询
 首页
首页 数据总线DataHub-阿里云自研数据总线
数据总线DataHub-阿里云自研数据总线提供对流式数据的采集、存储、分发功能。用户可以基于DataHub轻松构建基于流式数据的分析和应用。【数据采集】:提供SDK、插件、兼容Kafka Producer协议,帮助您采集各类业务数据。【数据存储】:采用存储计算分离架构,计算避免数据热点,存储使用自研盘古系统,具备高安全、多副。本、强稳定的特点,SLA达99.99%【数据投递】:支持涵盖几乎所有阿里云计算引擎,系统无缝对接,连接性好。

产品技术架构负责用户的接入,同时会对Data进行格式化,然后传给Xstream。与pangu的存储集群交互,读写数据, 同时有Metric采集,资源回收等模块。负责将DataHub中的数据同步到其他产品,处理订阅的创建删除,协同消费以及订阅点位的保存和获取。所有模块均运行在Fuxi集群中,以Fuxi Service形式进行管理。系统采用存储计算分离架构,数据均存储与Pangu集群中,不依赖本地磁盘。

产品优势数据总线DataHub—数据采集数据采集:提供多种SDK、API和第三方插件以及Kafka协议,您可以实时接入APP、WEB、IoT和数据库等产生的异构数据,进行统一管理,消除数据孤岛。
数据总线DataHub-数据存储数据存储:灵活设置存储时间,保证下游系统可重新消费数据,自身自动提供数据多备份和存储加密,具备跨机房容灾功能,安全可靠。
数据总线DataHub-数据投递数据投递:提供DataConnector模块,简单配置即可把接入的数据实时同步到下游系统(如MaxCompute、OSS、TableStore等主流系统)极大减轻了数据链路的工作量,实现一投多消。
最新特性阿里云DataHub典型场景-金融行业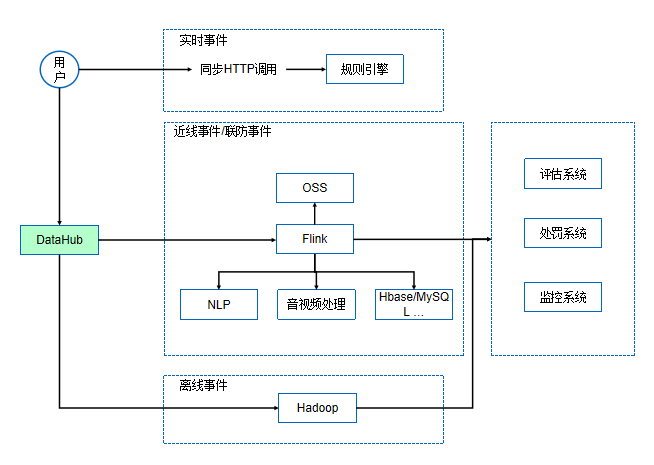 阿里云DataHub典型场景-电商/物流行业
阿里云DataHub典型场景-电商/物流行业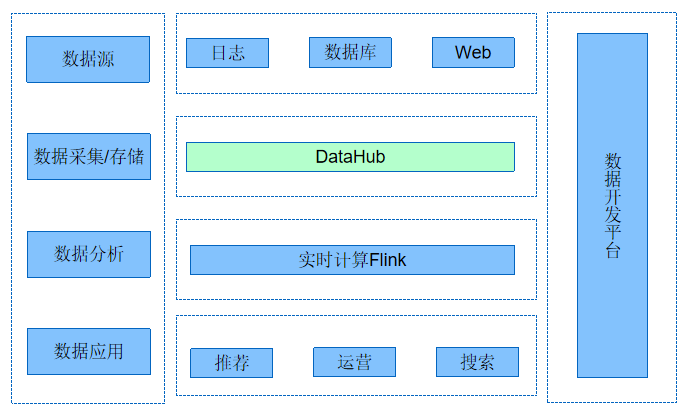 阿里云DataHub典型场景-在线教育/公共安全行业
阿里云DataHub典型场景-在线教育/公共安全行业 阿里云DataHub典型场景-IOT行业
阿里云DataHub典型场景-IOT行业 阿里云DataHub典型场景-互联网
阿里云DataHub典型场景-互联网
产品推荐

企宗法务是科芯数服与腾讯电子签、企业微信联手打造的智能合同管理平台。提供从合同起草、合同审核、数字认证、合同签署、合同履约、合同归档、合同报表等全程数字化的合同管理能力,帮助企业解决合同管理难题,降低合规风险。

飞鸽传书 QT 局域网即时通讯软件,是适配信创需求的企业安全即时通讯工具,还集成多设备实时投屏互动通讯系统。依托局域网环境实现安全高效通讯,支持多设备投屏互动,保障企业数据传输安全,满足内部协同沟通需求,是信创企业局域网即时通讯的可靠选择。


中医聪宝素问中医大模型应用方案,整合智能中医诊疗与智能共享中药房管理系统。融合海量典籍、研究成果及临床知识,精准辅助诊疗,提供个性化方案。优化中药房管理,保障用药安全,赋能中医行业高效发展 。
数字化社区
视频
文章



