







云掣ACOS统一运维监控平台
立即咨询
 首页
首页 企业新发展带来的挑战云掣服务的优势
企业新发展带来的挑战云掣服务的优势 传统监控与可观测性的关系
传统监控与可观测性的关系监控(Monitoring):是以系统可用性为中心,收集、分析和使用明确的信息来观察一段时间内的运行进度,并且进行相应的决策管理的过程。可观测性(Observability):基于白盒化的思路,通过分析系统生成的数据,构建完整的观测模型,理解推演出系统内部的状态。

统一运维可观测套件ACOS--问题与方向统一运维可观测套件ACOS--功能大图 统一日志
统一日志 ACOS统一运维监控平台,让可观测运维更简单
ACOS统一运维监控平台,让可观测运维更简单





 安全生产可观测解决方案
安全生产可观测解决方案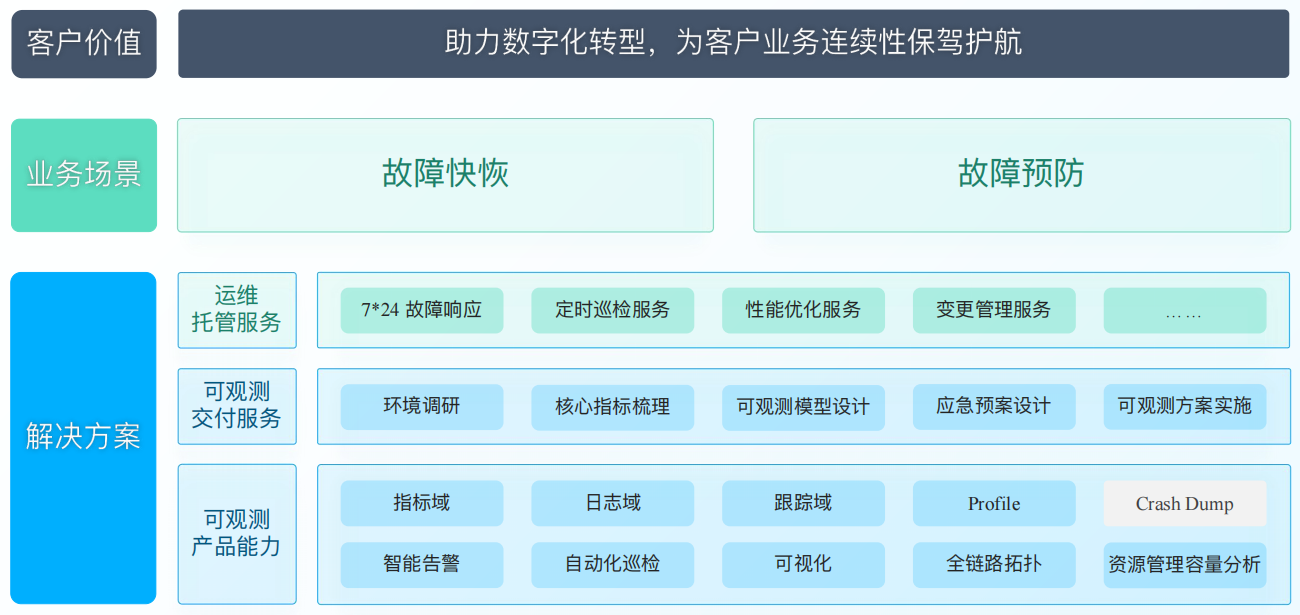 专业的运维托管服务--助力企业快速获取专业的运维能力
专业的运维托管服务--助力企业快速获取专业的运维能力 运维服务整体流程运维服务标准承诺
运维服务整体流程运维服务标准承诺
 解决方案
解决方案 案例一:某市健康码全链路监控
案例一:某市健康码全链路监控背景:XX市新型冠状病毒肺炎疫情防控工作领导小组办公室下发《关于我市持续巩固疫情防控成果有序复工复产的实施方案》,明确XX全面复工复产时间点和任务安排,XX大数据中心要求防疫相关的扫码等服务系统务必保证稳定性,支撑XX人民有序复工复产。痛点:ISV厂商众多,缺乏全局视角,快速定界厂商问题。业务链路复杂,出现故障后定位问题困难,缺乏全链路可观测视角。故障频发,被动响应,缺乏体系化故障梳理。时间紧、客户”因为看见,所以相信”,同时需求变动频繁。

案例二:某券商大数据平台升级扩容
 案例三:某电商迁云
案例三:某电商迁云 公司资质和荣誉
公司资质和荣誉 客户数字化转型的选择
客户数字化转型的选择
产品推荐

有道智云AI开放平台专注提供稳定、安全、高效的AI服务。网易有道旗下一个为开发者、企业和政府机构等提供自然语言翻译、文字识别OCR等服务以及行业解决方案的云服务平台。致力于提供安全,可靠和高效的云服务。

天空卫士云安全服务平台是一种基于云的数据安全解决方案,企业和组织可以灵活选择搭配各种数据安全服务,对其数据和应用进行保护,以满足以下业务需求在统一的视图中实时监控企业数据资产分布及潜在风险,企业数据安全状况一目了然;集成数据管理能力,保证企业 IT 系统上云以后,仍然能满足合规要求;提供包括敏感内容识别、数据分类分级等安全选项, 保护云端数据安全;监控云端数据,并预判潜在威胁,提前加以防范。


51社保的所有服务均100%线上化,时效提高,服务可溯,结果可验。而且,我们还开放API系统对接,成熟的技术研发团队可以做落地实施,目前薪酬社保等已有几十家采用系统对接。引领人力资源服务行业迈入互联网时代。让客户乐享更高效率、准确履约交付和极致体验。



