







达观数据舆情分析与智能文本处理方案
立即咨询
 首页
首页 解决方案-提出思路数据采集:支持爬虫抓取、本地、接口等方式
解决方案-提出思路数据采集:支持爬虫抓取、本地、接口等方式利用爬虫技术获取微信公众号、网站数据 ——从指定的网站进行相关信息抓取,存储到原始库,供系统分析使用
 数据清洗:去噪初步处理提升数据质量
数据清洗:去噪初步处理提升数据质量数据清洗(Data cleaning)是对数据进行重新审查和校验的过程,目的为删除重复信息、纠正存在的错误、剔除无效数据、数据一致性。——例如:广告、重复、无效网页、无效内容、关联性验证。

文本挖掘文本预处理利用自然语言处理技术、机器学习、深度学习算法,对文本数据进行分析。 ——例如:评论、留言、文章、销售记录

智能分析-业务模型构建基于语料库、标注数据、经验规则,利用自然语言处理技术、机器学习、深度学习算法,将数据处理结构结合业务需求生成模型。 ——支持噪声识别模型、危机识别模型、舆论分类模型、情感分析模型、媒体影响力模型、热词分析模型、新闻溯源模型

可视化管理分析——自定义统计图表可视化管理分析——数据可视化 可视化管理分析——文本检索
可视化管理分析——文本检索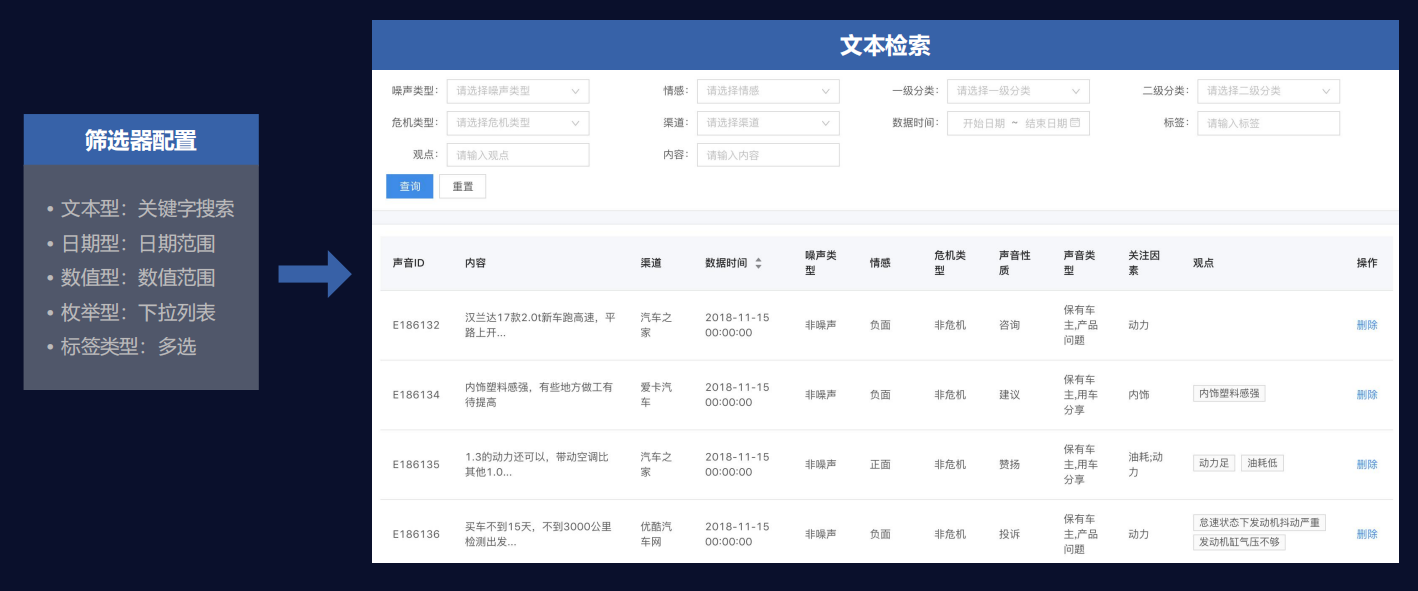 可视化管理分析——危机预警
可视化管理分析——危机预警 其他产品功能达观数据舆情分析系统总体架构
其他产品功能达观数据舆情分析系统总体架构 优势1:NLP与机器学习技术提高长短文本分析准确度
优势1:NLP与机器学习技术提高长短文本分析准确度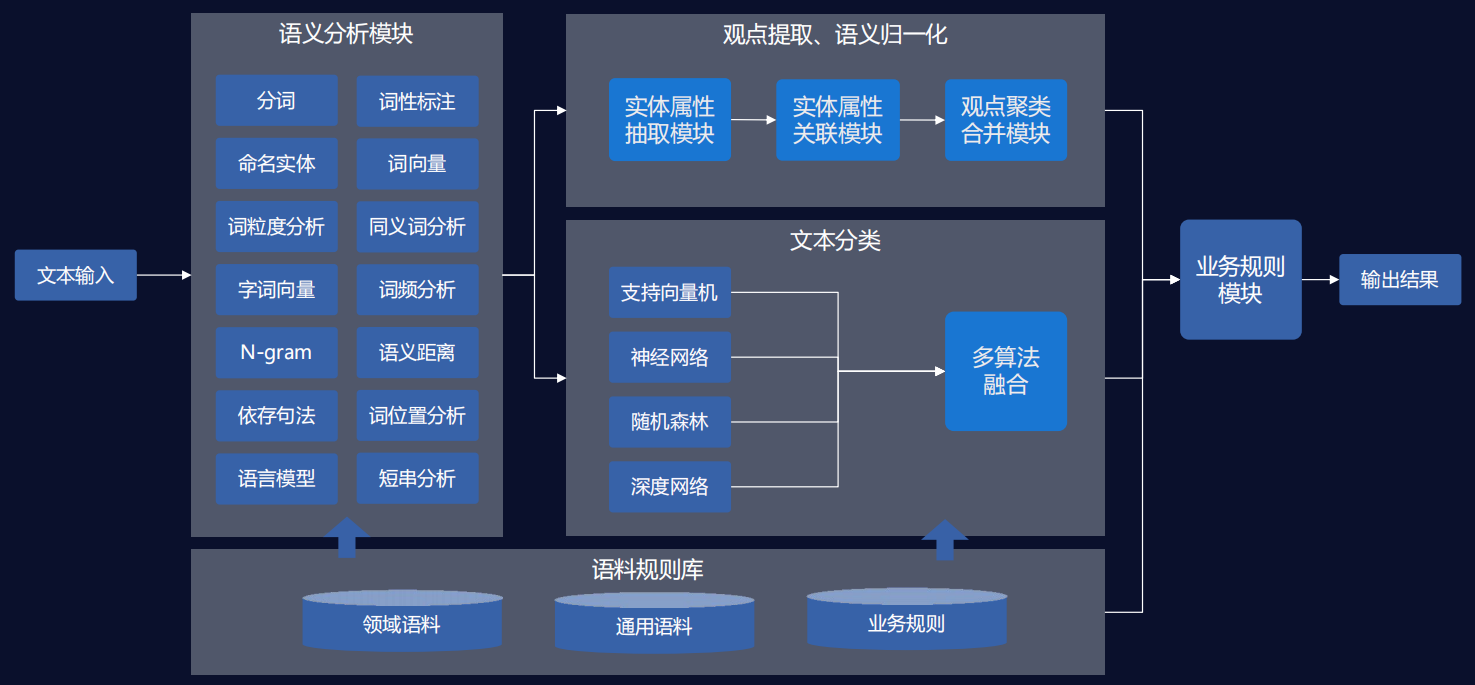 优势2:全面监控危机及时预警
优势2:全面监控危机及时预警实时监控数据源,可结合多种预警方式自动识别危机事件,预警消息及时通过站内、邮件的方式通知相关人员
优势3:机器学习模型结合人工反馈机制不断优化效果 某所智能情报事件分析系统
某所智能情报事件分析系统 智能VOC客户声音分析平台
智能VOC客户声音分析平台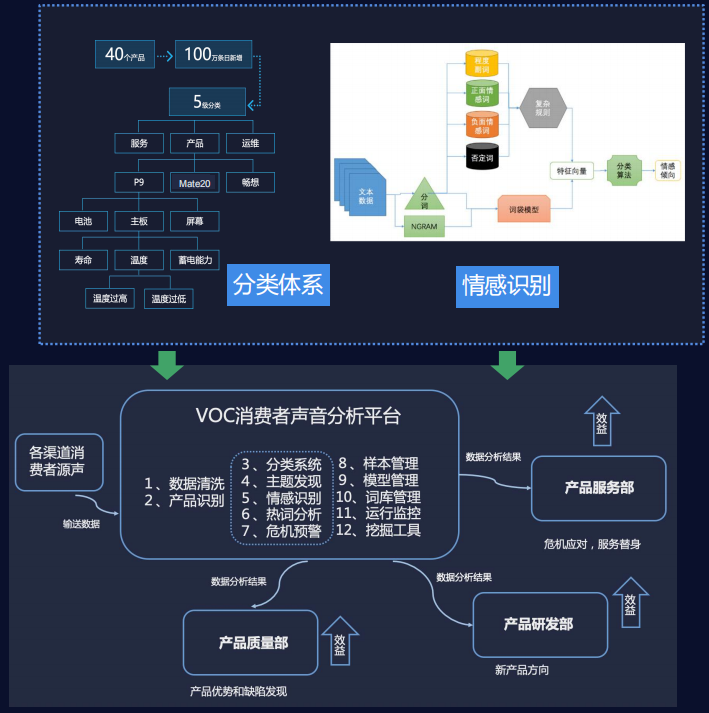 智能VOC舆情分析系统
智能VOC舆情分析系统 虎扑识货评论文本标签提取及质量打分
虎扑识货评论文本标签提取及质量打分 系统交付方式
系统交付方式 达观数据无微不至的后续服务达观数据:专注于文本智能处理的高科技创业企业
达观数据无微不至的后续服务达观数据:专注于文本智能处理的高科技创业企业 达观数据:资质最全、权威认证的国家高新技术企业
达观数据:资质最全、权威认证的国家高新技术企业拥有国家级高新技术企业认证、CMMI3软件成熟度认证、ISO9001质量管理体系认证、ISO27001信息安全管理体系认证、国家双软认证等全面的企业资质。先后成为微软加速器、百度AI加速器、青藤大学、联想之星、SAP、普华永道创新营成员,中国人工智能学会自然语言理解专委会企业会员,同时也是中文开放知识图谱平台OpenKG的发起成员之一。


荣获行业和媒体认可最多的文本智能处理企业成功为各行业知名企业提供文本智能处理系统 成功为众多新兴科技和互联网企业提供技术服务
成功为众多新兴科技和互联网企业提供技术服务
产品推荐

璞华采云链SRM,领先的采购管理系统与供应商管理软件。从采购需求发起,到供应商寻源、采购执行及供应商绩效评估,全程数字化管理。有效提升采购效率,优化供应链,强化企业与供应商协同,为企业降本增效,筑牢供应链竞争力。

百炼智能Aideas智能营销应用市场,一站式应用市场,更高效能、更低成本地实现生意倍增,数据底座+算法模型+行业知识+场景化平台,即开、即用、即通的智能营销全链条商业应用。

泛微e-cology9数字化管理平台社交化协作,工作微博,记录工作点滴。协助区以事件为主线,将所有的工作按照每一个事件类型来分类。即时通讯,实现管理从“人找事”到“事找人”的转变,将企业各类消息提醒服务统一到一个界面。

腾讯电子签 SaaS 版提供成熟的合同管理平台及一站式的企业端服务管理能力,支持合同全生命周期管理,电子印章的使用及管理。结合小程序端的产品形态,用户可轻松在移动端/pc端完成合同发起至签署的操作闭环。



