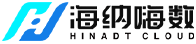犀语科技智能文档解析平台
 首页
首页 企业数字化转型中面临的痛点
企业数字化转型中面临的痛点根据企业的数字化成熟度不同, 可以将企业数字化转型所处的阶段分为在线化、集成化、数字化、智能化四个阶段。目前中国大部分传统企业处于在线化和集成化阶段,少数企业进入数字化阶段。智能化的局部应用已经出现,大规模成体系地应用在传统企业的情况尚不多见。
产品概述以数据价值为基础,人工智能分析为引领,搭建企业全局数据平台和智能分析系统,为企业运营管理的所有环节提供分析洞察,并从分析运营结果向预测未来发 展转化。妨碍企业整合数据分析平台建设的因素包括技术和部门墙带来的数据隔离,后者是目前更主要的障碍。AI 应用场景与开发环境、常用 AI 数据模型,以及数据库整合在一起,形成企业 AI中台,将各种AI能力汇聚在一起,对不同业务提供 AI 能力,并形成具备AI服 务能力的中台。数字化时代企业需要具备敏捷的反应能力,对外应把握客户和市场的迅速变化,对内满足企业管理要求。敏捷能力的建设需要业务模式、 IT 架构、产品开发方式 同时实现敏捷,从而孕育低代码平台的产生。
产品矩阵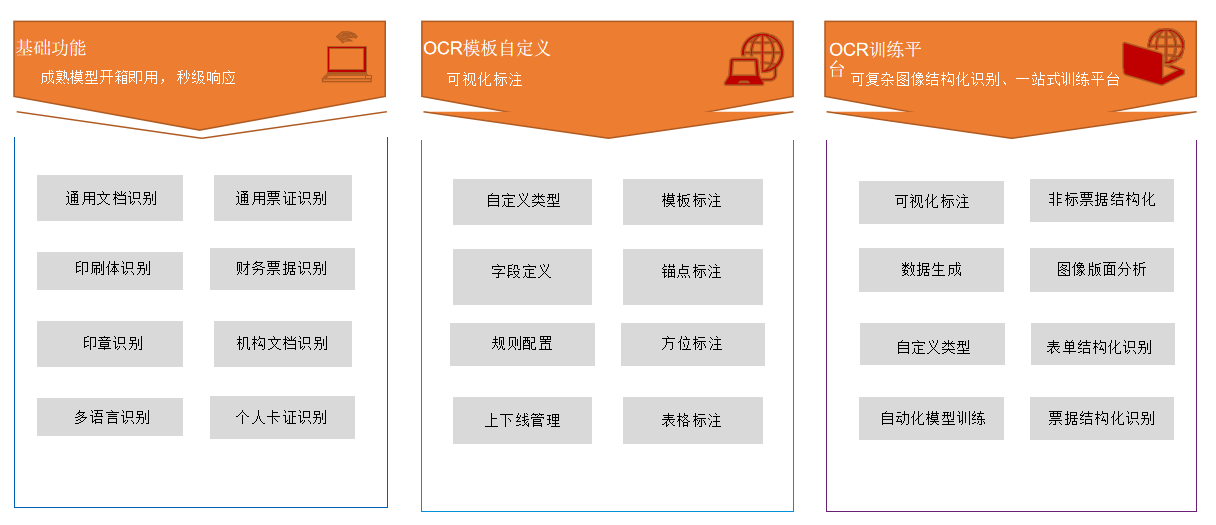 文字识别能力
文字识别能力文字识别+图像识别技术将各位常见文档图片或文档扫描件中的信息按照文档原有的格式进行文本识别和还原

票证识别能力 支持40+票证结构化识别 模板识别自学习
模板识别自学习1个样本制作模板,即可实现对相同版式样本的结构化识别

OCR训练平台一站式OCR识别训练平台,少量样本即可训练高可用模型, 结构化输出关键字段内容, 极大提升OCR模型训练效率

智能信贷报告审阅方案 关键信息摘取(NLP)
关键信息摘取(NLP) 通用文本识别(OCR)
通用文本识别(OCR) 智能抽取(OCR+NLP)
智能抽取(OCR+NLP) 知识库搭建
知识库搭建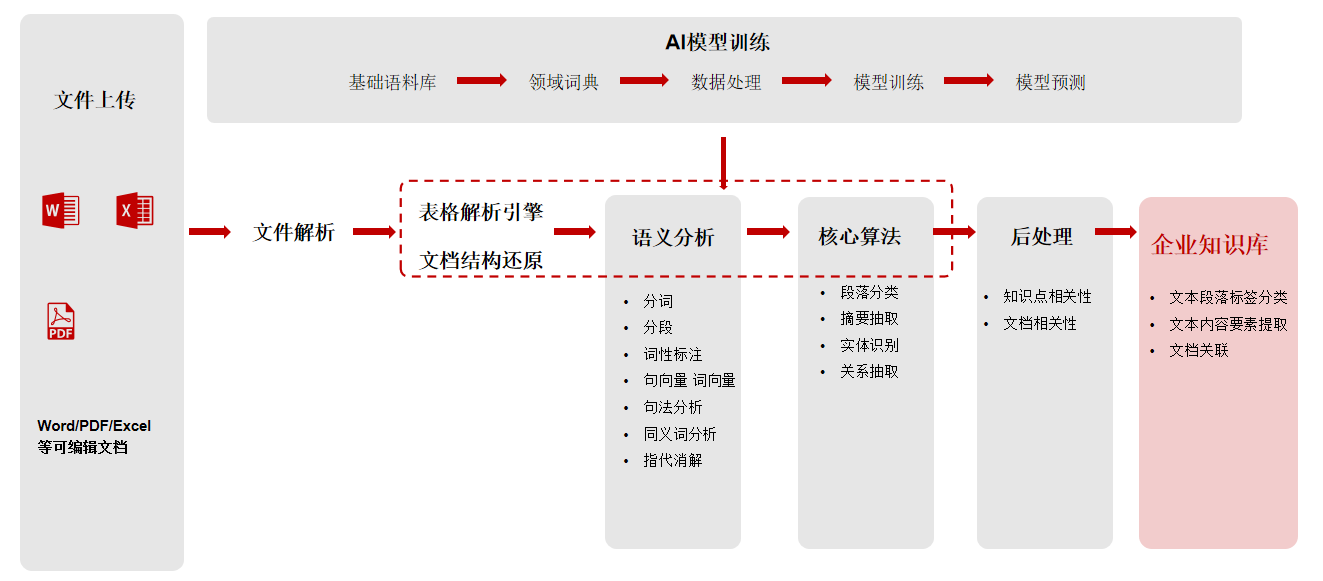 系统功能架构
系统功能架构 犀易工场功能架构 – CV+NLP 方向
犀易工场功能架构 – CV+NLP 方向 应用关系示意
应用关系示意 生产环境数据修正反哺AI工厂模型训练示意
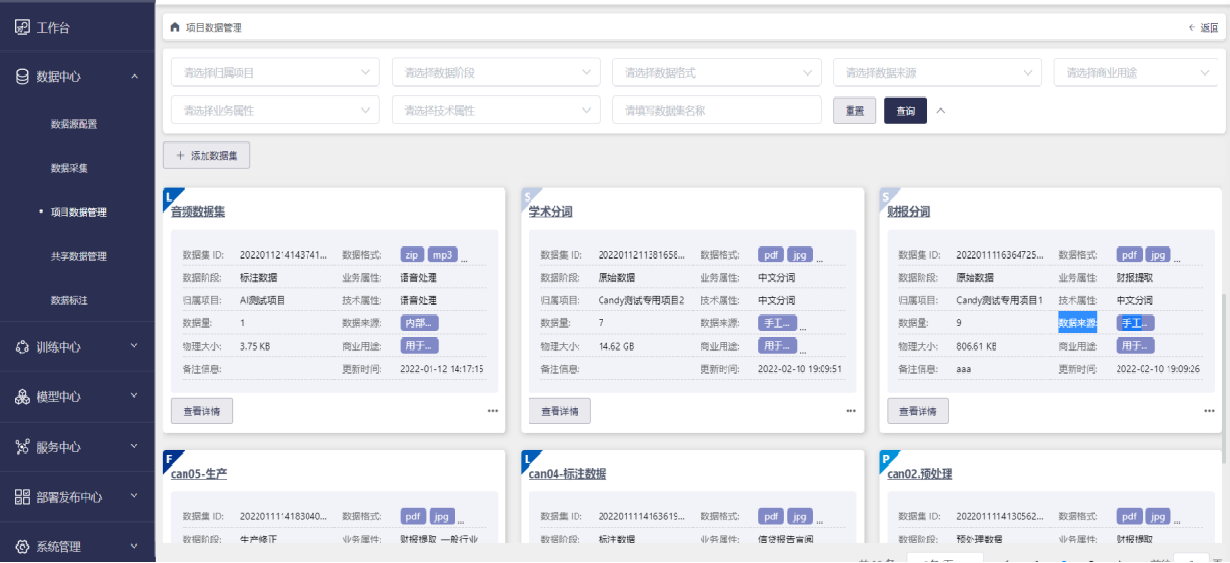
生产环境数据修正反哺AI工厂模型训练示意 犀易工场对非结构化数据在不同阶段的管理支持
犀易工场对非结构化数据在不同阶段的管理支持结合非结构化数据提取的一般特征,我们在数据集管理中设计了若干标签,其中一类是按照模型开发生命周期,划分为:原始数据,预处理数据,标注数据,生产修复数据,最终优质的标注数据会合并线下多批次标注数据和生产反馈清晰后的数据,形成优质非结构化数据集。
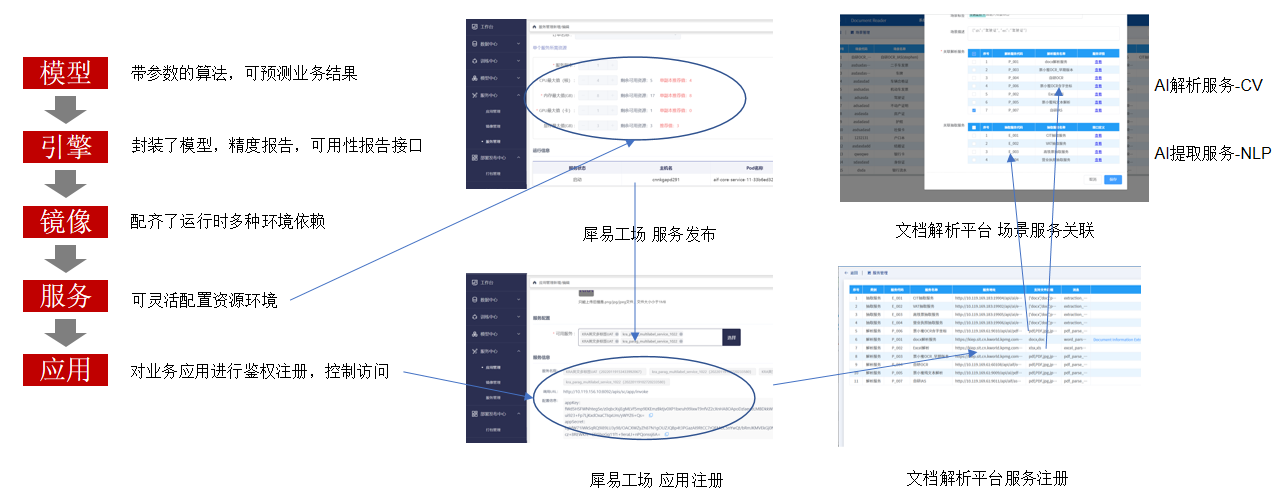
 新场景配置和犀易工场对接示意
新场景配置和犀易工场对接示意服务中心是犀易工场的面向应用提供AI服务的管理中心,提供了镜像管理、服务管理、应用管理等基本功能。服务中心可以和训练中心耦合部署,支持在开发环境进行服务赋能,服务中心也可以和智能应用耦合部署,支持在生产环境进行服务赋能。
业务数据和模型训练在模型精度和保密控制间如何平衡 单场景多套提取字段配置示意
单场景多套提取字段配置示意在文档解系平台的赋能实践中,我们发现,由于数据特征的差异和业务诉求的差异,往往针对一个场景的文档会涉及多套提取诉求,但针对每类提取模型的训练是需要时间的。因此从快速,分步骤赋能业务的思路来看,需要在文档解析完成后,优先给业务提供灵活的输出结构配置,供业务选择输出模板,人工划选提取。当然针对通用的字段,NLP模型可以统一辅助提取,而随着数据的不断积累,小类中特征明确的子类,可以拆分衍生为新的场景,通过专项NLP模型训练,完成场景闭环,实现端到端提取能力。

AI工厂标注后数据样例展示AI工厂提供多种标注工具,每类标注工具有其特有的输出标准。以文档提取类和对话提取类最常见的命名实体标注来举例,通过配置提取标签,在线划选弹出,选择标签,正文高亮显示形成如下标注样式,具体输出如下示意:

服务客户
产品推荐