






思必驰平板音频解决方案
立即咨询
 首页
首页 通话场景痛点思必驰AI背景降噪
通话场景痛点思必驰AI背景降噪核心算法基于传统信号处理+深度学习技术,结合麦克风阵列进行前端降噪,不受限于噪声类型,覆盖低信噪比全场景,大幅提升通话清晰度,改善噪声环境下的通话质量;双麦/四麦算法,分全向模式和定向模式,最远支持双麦3m/四麦5m拾音降噪。定向模式可以针对固定角度 进行音频增强。单麦算法,适合近场,可搭配耳机一起使用。
 性能表现优秀Dmic降噪效果对比_手机铃声测试,距离mic最近距离 1cm
性能表现优秀Dmic降噪效果对比_手机铃声测试,距离mic最近距离 1cm Dmic降噪效果对比_定向干扰人声消除测试
Dmic降噪效果对比_定向干扰人声消除测试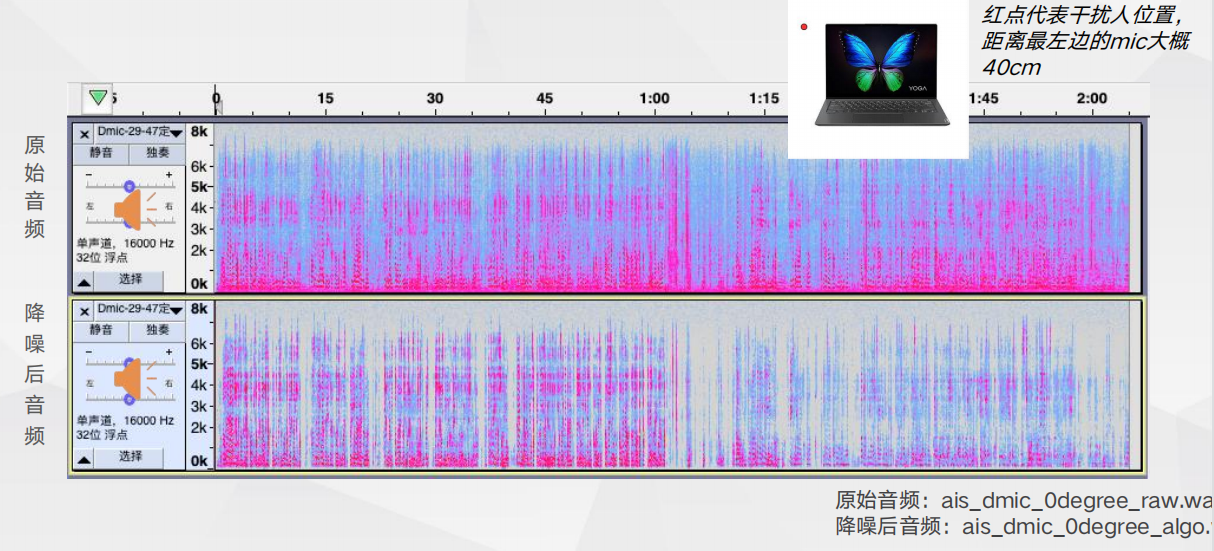 Dmic降噪效果对比_单点干扰源噪声测试
Dmic降噪效果对比_单点干扰源噪声测试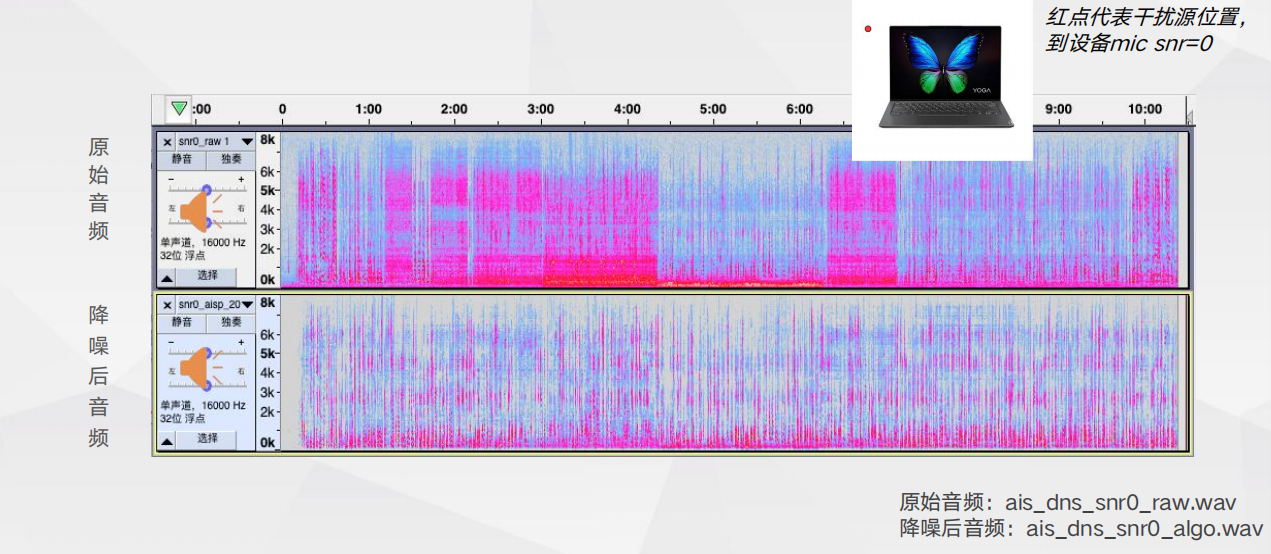 Amic(3.5mm)降噪效果对比_单点噪声测试
Amic(3.5mm)降噪效果对比_单点噪声测试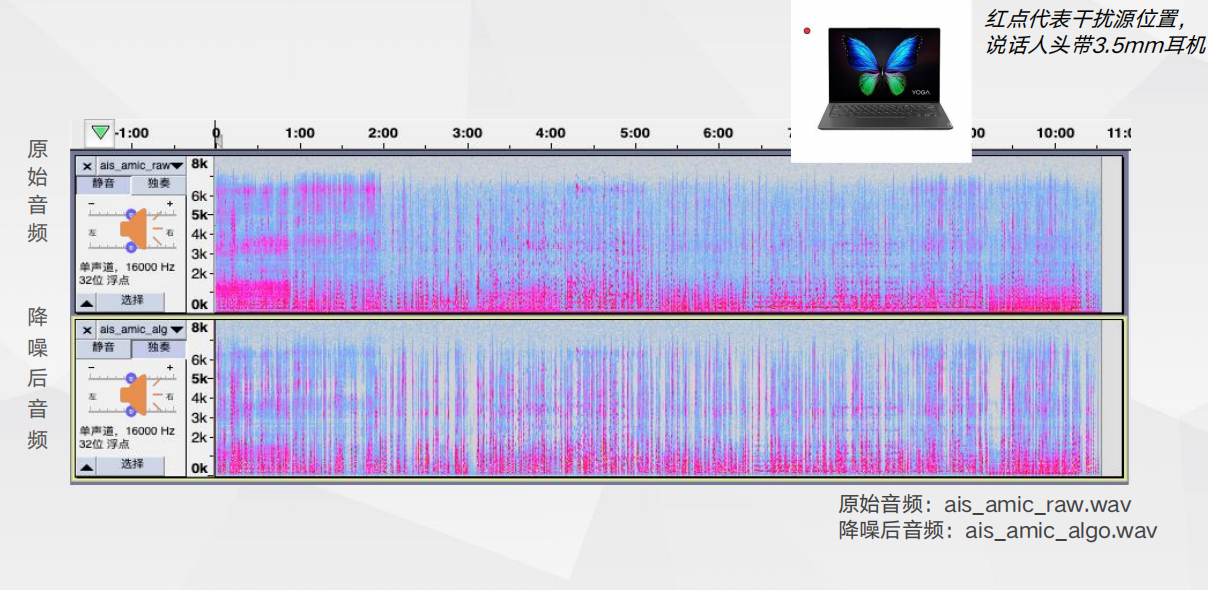 上行通话降噪plus,只保留主说话人声音——NFP方案
上行通话降噪plus,只保留主说话人声音——NFP方案只保留扇形区域主说话人声音,去掉扇形区域外背景噪声和干扰人声,最左最右麦克风间距240mm,扇形区域半径50cm。
 上行通话降噪plus,只保留主说话人声音——NFP方案音频效果
上行通话降噪plus,只保留主说话人声音——NFP方案音频效果 上行通话降噪plus,只保留主说话人声音——多模态交互方案
上行通话降噪plus,只保留主说话人声音——多模态交互方案 上行通话降噪plus,只保留主说话人声音——声纹voice filter方案
上行通话降噪plus,只保留主说话人声音——声纹voice filter方案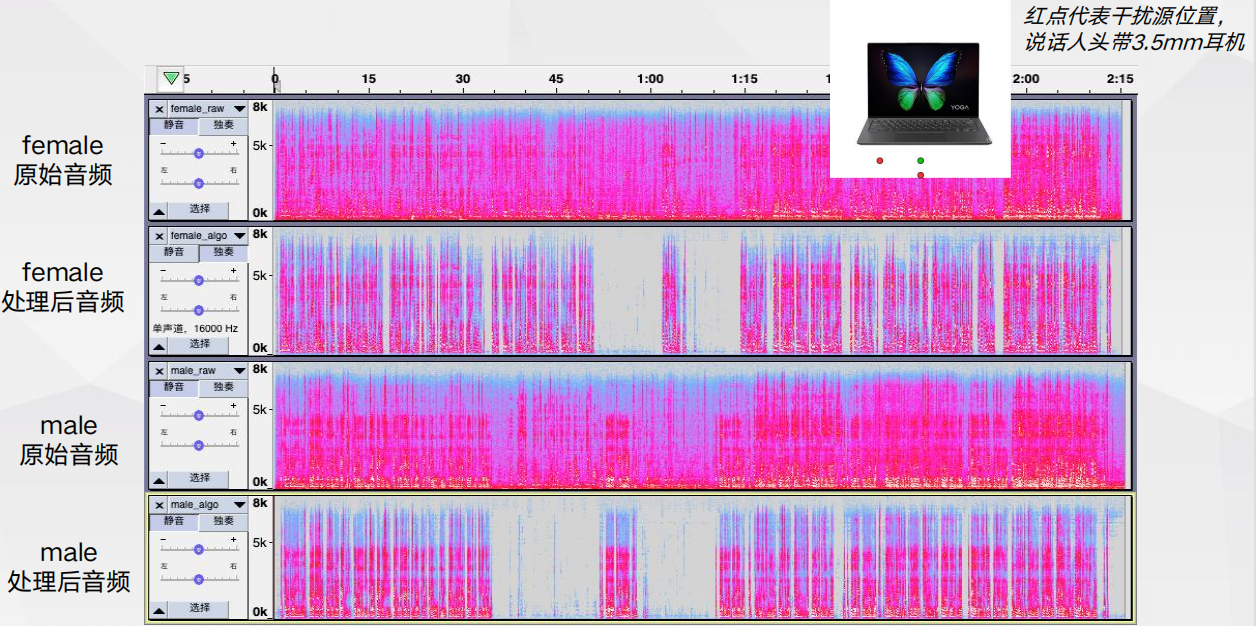
远端降噪——下行通话降噪
目前业界语音降噪方案更多是对近端进行降噪,远端降噪/下行通话降噪 可以消除对方传过来的背景噪声,即使对方所在背景环境噪音嘈杂,仍然可以听到对方清晰的通话内容;
支持喇叭播放/3.5mm耳机输出;
噪声模型能识别并消除多种噪声类型,并持续迭代升级;
噪声抑制深度30dB+。
带来的客户价值对接流程清晰,周期短 全链路语音服务ASR主要产品类型产品优势声纹注册、验证过程
全链路语音服务ASR主要产品类型产品优势声纹注册、验证过程 声纹确认示例
声纹确认示例 训练平台能力蓝图
训练平台能力蓝图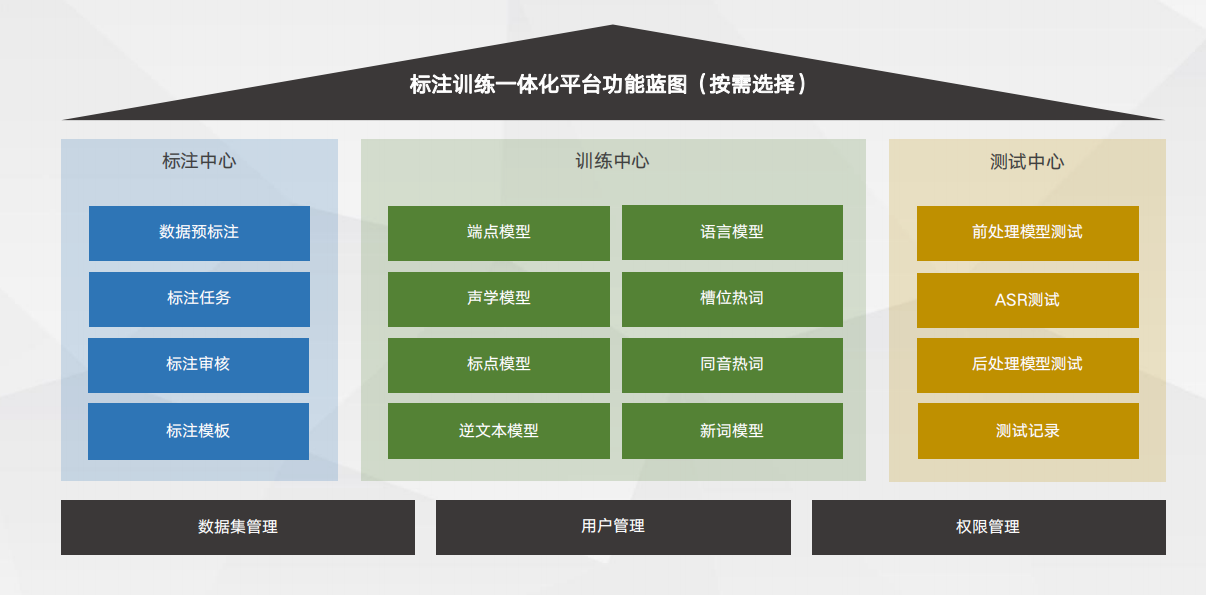 定制专属模型,优化识别效果
定制专属模型,优化识别效果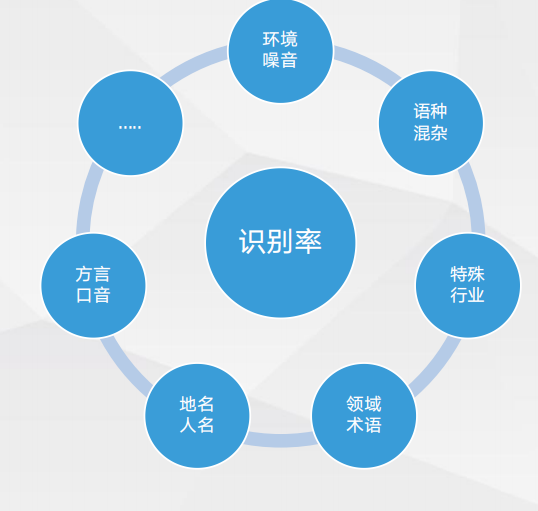 缩短交付生产链路,提高规模化定制能力
缩短交付生产链路,提高规模化定制能力已有的研发交付链路长,沟通成本高,用户在开发过程中过度依赖语音厂商,自主权不够。 思必驰DUI标注训练一体化平台,将数据标注和模型定制能力赋能用户,大大优化了生产链路。用户可独立完 成所有流程,语音厂商不参与其中,满足规模化生产需求。
 训练标注一体化平台优势标杆案例
训练标注一体化平台优势标杆案例 主动降噪(ANC)
主动降噪(ANC)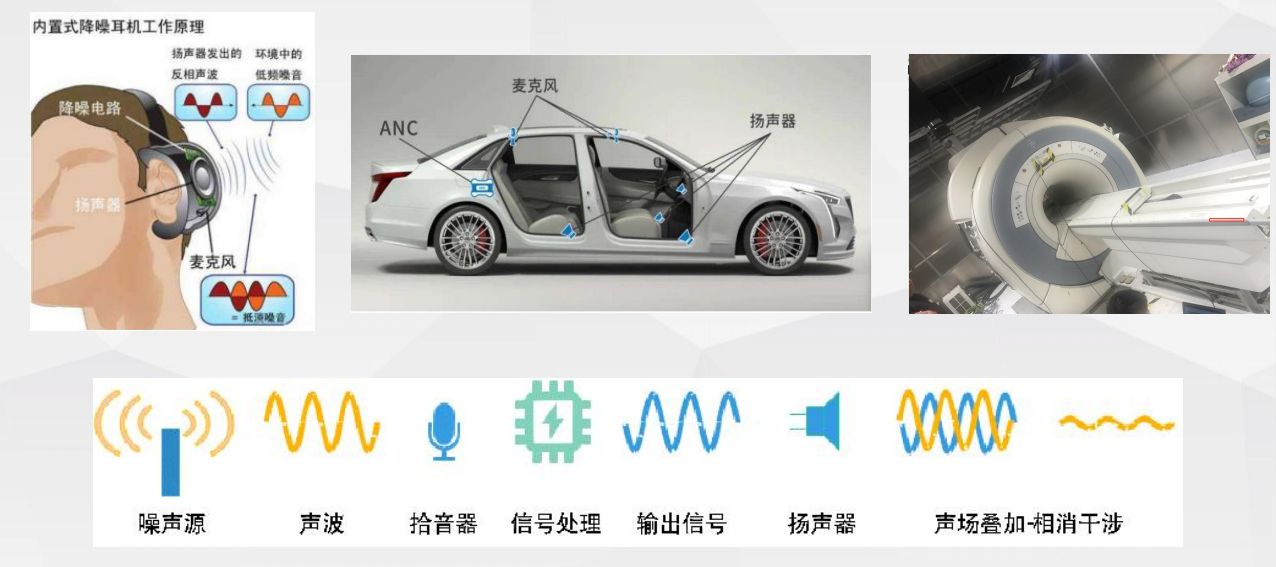 思必驰PC ANC_自适应控制方案
思必驰PC ANC_自适应控制方案疫情下,用户通常通过PC居家办公或打游戏,当CPU负载较高或者用户在玩高负载的游戏应用时, 风扇噪声会逐渐增大,会干扰到用户的使用体验。 通过探索一种区域性降噪的技术,让处于该区域的人员人耳接收到的风扇声音明显降低, 从而提高用户的使用体验

产品推荐

锐捷普教极简以太彩光网络解决方案,整合普教二层无源全光组网系统与彩光传输校园网系统。可实现校园网络无源化部署、彩光高效传输,适配中小学教室、图书馆等场景,简化布线与运维,降低成本,保障网络稳定,助力普教构建极简、高效的校园网络环境。

ZEGO即构虚拟场景解决方案,支持文本、表情、图片、语音、视频、文件、自定义消息等全消息收发,玩法丰富多样化。 提供单聊、群聊、聊天室等多种会话形式,支持高并发消息处理,多端消息同步,群组成员管理。支持多种推送方式,如广播推送、用户发送、标签发送,及时地向应用程序的用户推送通知或者消息。
艾利特协作机器人是面向柔性制造的新一代灵巧机器人,重量轻、体积小、功能强大能更灵活地满足应用和行业需求,适于搬运、装配、检测等多种工艺和应用。高负载自重比,部分机型性能远超过国外同类产品完善的安全功能和高等级的产品性能,国际领先。灵敏的拖拽示教和面向应用的界面设计,入手简单、示教简单。高自研率+面向应用的产品快速迭代能力,性价比高。完善的二次开发接口和界面扩展能力,通用性强。

极智算AI算力运营及调度平台,提供高性能GPU集群租赁服务,依托算力池化与云调度技术,实现算力高效分配与灵活调度。适配AI训练、深度学习等场景,优化算力资源利用,为企业及科研机构提供稳定、高效的智能算力解决方案,助力业务高效推进。
数字化社区
视频
文章



