







有道智云AI数字人
立即咨询
 首页
首页 行业痛点 有道数字人平台概述
行业痛点 有道数字人平台概述 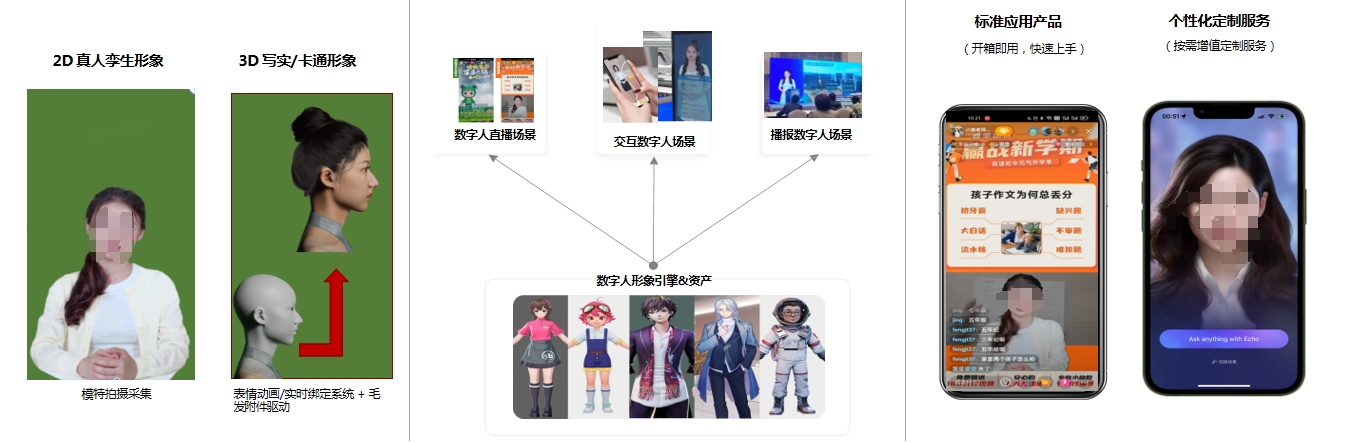 有道数字人形象定制
有道数字人形象定制 基于对真人形象视频的表情和肢体动作, 通过表征向量计算、词义算法理解、语音识别、语音合成、3D人脸识别、人脸视频合成、语音驱动口唇、肢体动作合成技术 进行1:1复刻数字人模型,模型训练完毕后可以直接上线数字人系统,通过文本或录音生成直播数字人、播报数字人、交互数字人
 有道数字人形象定制 视频拍摄格式
有道数字人形象定制 视频拍摄格式  实时语音识别
实时语音识别 支持8 种常用语言识别 44 种小语种的语音识别;支持中 英、中川、中粤等方言; 支持标点符号、文本顺滑、文本自动分段、数字归一化;
语音合成  形象引擎多终端适配
形象引擎多终端适配  零售场景
零售场景  汽车场景
汽车场景  教育场景
教育场景 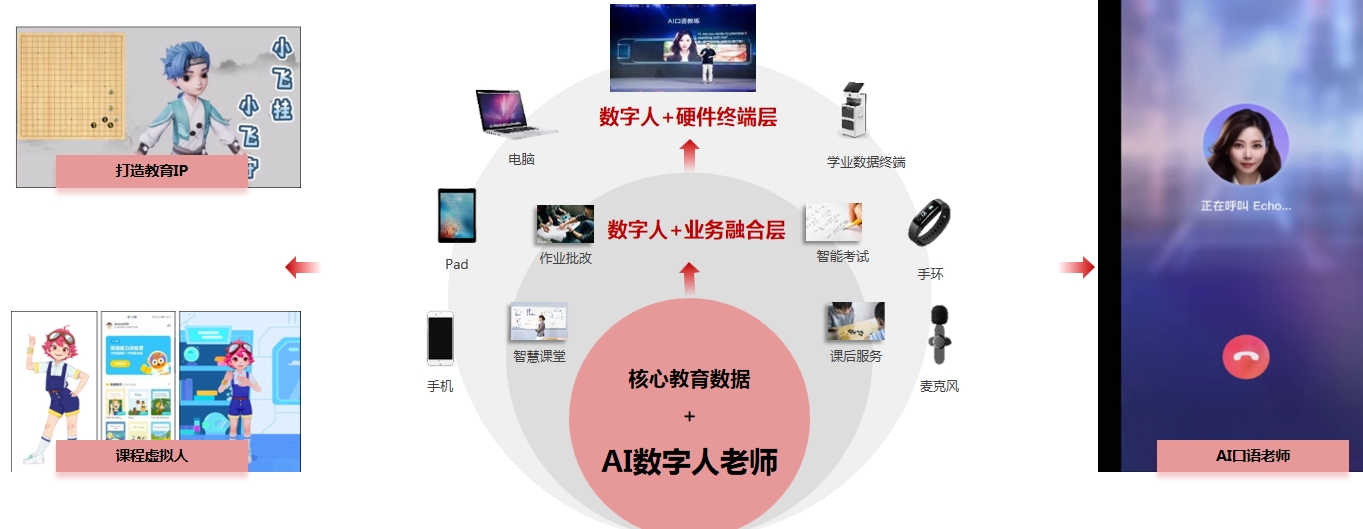 直播数字人的优势 直播数字人
直播数字人的优势 直播数字人  直播数字人
直播数字人  直播数字人
直播数字人  播报数字人的优势 播报数字人
播报数字人的优势 播报数字人  播报数字人
播报数字人  播报数字人
播报数字人  交互数字人的优势 交互数字人
交互数字人的优势 交互数字人  交互数字人
交互数字人  交互数字人
交互数字人 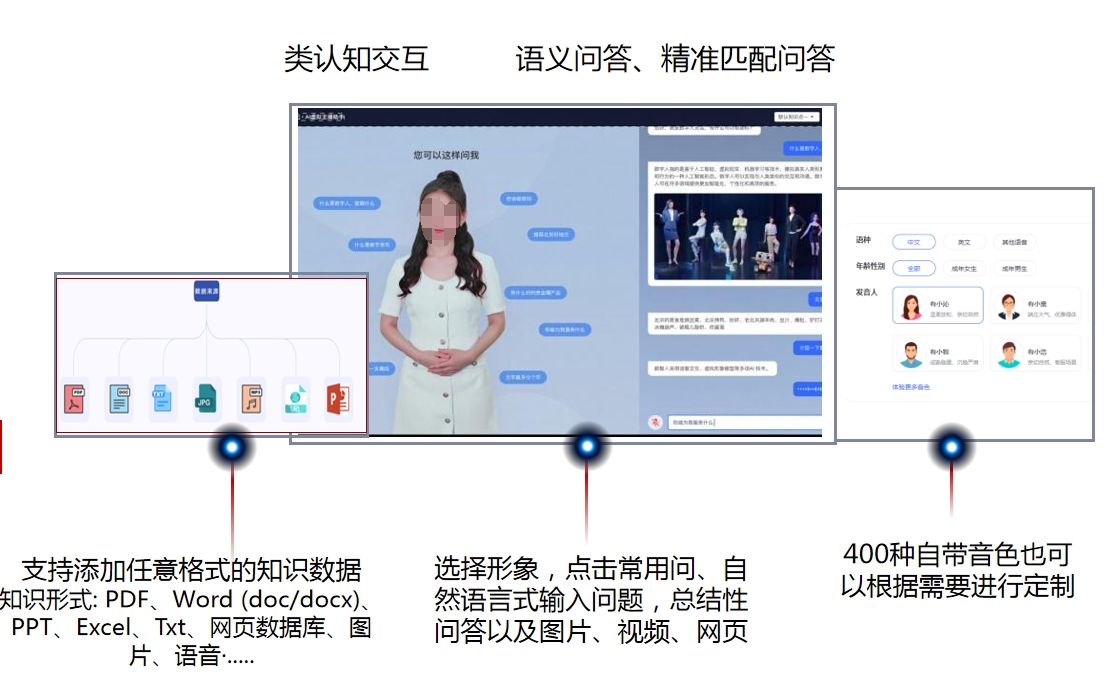 交互数字人
交互数字人  交互数字人
交互数字人  交互数字人 多品类多维度展示
交互数字人 多品类多维度展示 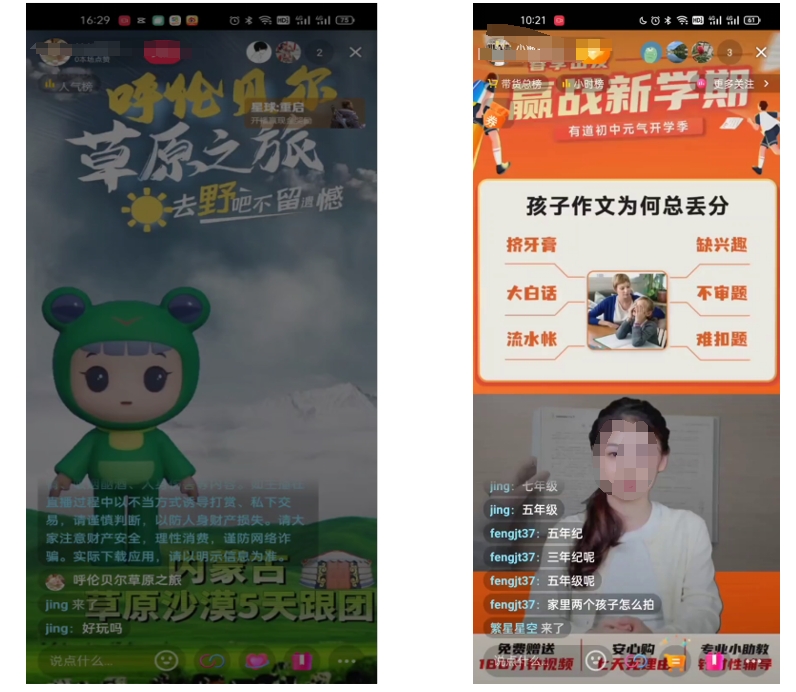 更多数字人场景
更多数字人场景  有道智云┃专注提供稳定、安全、高效的AI服务
有道智云┃专注提供稳定、安全、高效的AI服务  有道智云┃AIGC数字人技术架构
有道智云┃AIGC数字人技术架构  有道智云┃大模型研发体系
有道智云┃大模型研发体系  部分行业客户
部分行业客户 机器翻译市场第一;模型算法,覆盖网易有道全产品线;厚积薄发,AI赋能全行业全场景;自研AI平台,丰富的对接方式

产品推荐

中国电子云数据港“蓝盾”数据服务产品是基于央企的数据运营优势,与公安部一所和国家反诈数据重点实验室等机构深度合作,在获得主体授权的前提下,为企业提供包括员工背调、反舞弊、合作反欺诈、合规审计、供应链排查等丰富的综合数据服务。

永洪金融行业大数据可视化分析运营方案,提供高效、易用的数据分析平台,用户可以进行自服务数据准备、自服务数据分析,根据灵活需求,及时创建、修改报告,更快捷、准确的获取数据、分析数据,形成信息。随着不断积累,形成多个数据应用。

作为《Gartner 2020软件成分安全分析市场指南报告》中唯一推荐的中国产品——默安科技自主研发的SCA,是默安雳鉴DevSecOps全流程解决方案的重要组成部分,帮助客户管理应用中第三方组件所带来的安全、质量以及许可证合规性等方面的问题,避免第三方组件带来的风险。

RG-ONC-DC开放网络控制器采用Java OSGi模块化技术架构,在满足软件包可扩展的同时,支持组件在线升级,并兼容多个版本同时运行。RG-ONC-DC是锐捷网络针对数据中心类场景推出的SDN控制器产品。



