






偶数科技Skylab实时湖仓数据平台
 首页
首页 Skylab实时湖仓数据平台
Skylab实时湖仓数据平台
Skylab 核心组件包括云原生分布式数据库 OushuDB、自动化机器学习平台 LittleBoy、数据分析与应用平台 Kepler、数据资产管理平台 Orbit、数据开发 与调度平台 Flow、数据工厂Wasp 和系统管理软件 Lava
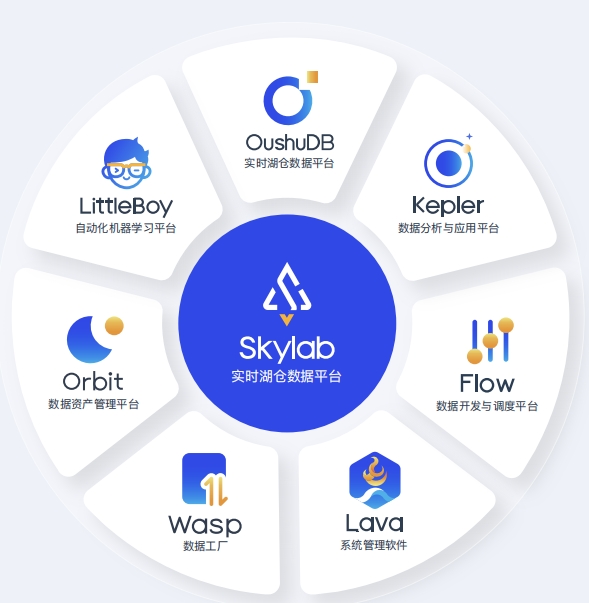
Skylab 实时湖仓六大特性凭借着卓越的产品能力,Skylab 实时湖仓数据平台已经成为用户构建云数据平台和湖仓一体平台的最佳选择。Skylab 率先实 现了ANCHOR 六大特性:All Data
Types支持多类型数据、Native on Cloud 云原生、Consistency数据一致性、High Concurrency 超高并发、One Data in Open Format一份开放格式数据、
Realtime 实时T+0。通过 ANCHOR 六大特性,Skylab 真正在数据和查询层面形成一体化架构,彻底解决集群规模和并发受限、非结构化数据无法整合、建模路径冗长、数据一致性弱、性能和时效瓶颈等问题,从而帮助用户彻底规避数据孤岛,优化数据供给能效,有效降低IT 运维成本和数据管理技术门槛,让企业在数字化转型过程中赢得先机
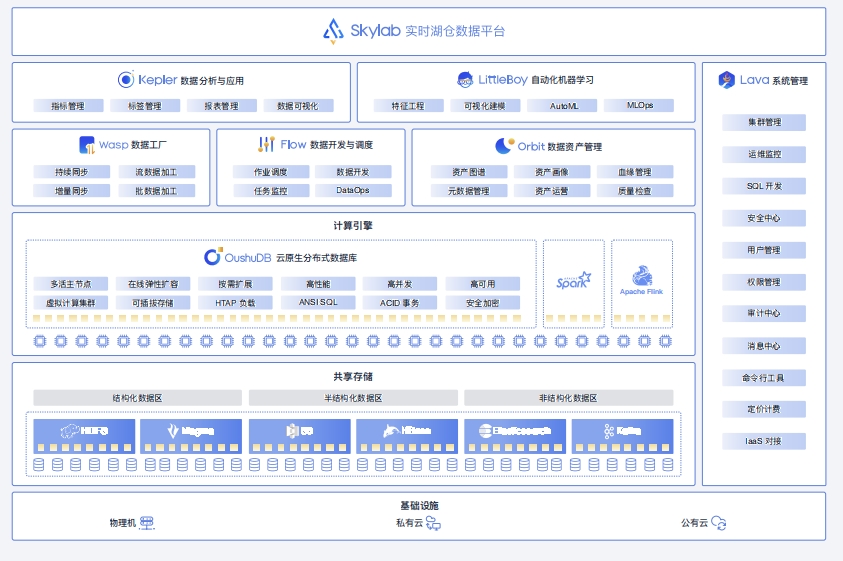
Skylab 平台架构
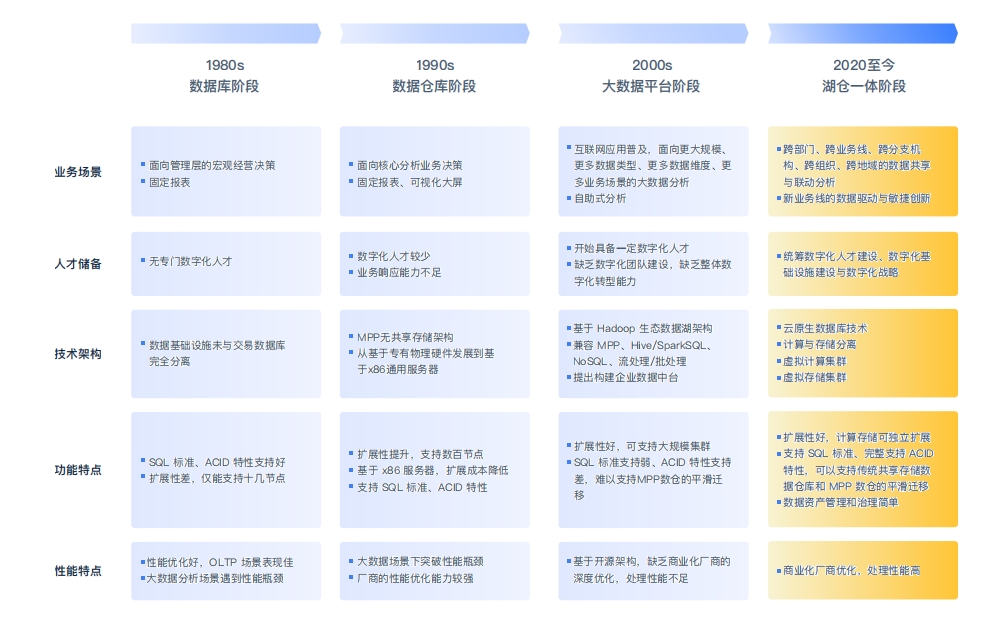
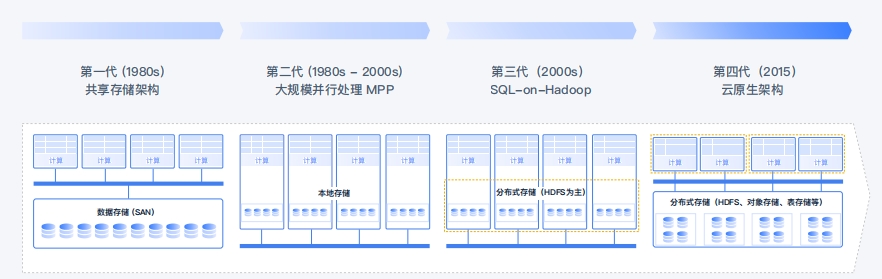
数据平台发展的不同阶段
OushuDB 云原生分布式数据库OushuDB 是由偶数科技自主研发的云原生分布式数据库,具有高性能、高并发、高可用的技术优势。OushuDB 兼容国产软硬件平台,符合国家信创标准。新一代执行器显著提升批处理和按需即席查询效率,面向 PB 级大数据的复杂查询,OushuDB相比传统 MPP 和 SQL-on-Hadoop快一个数量级。采用计算存储分离架构深度优化数据库的扩展能力,支持腾讯云、阿里云、华为云、金山云、微软 Azure、AWS 等主流云平台,充分满足云端应用高度弹性、无限扩容的要求
OushuDB 技术架构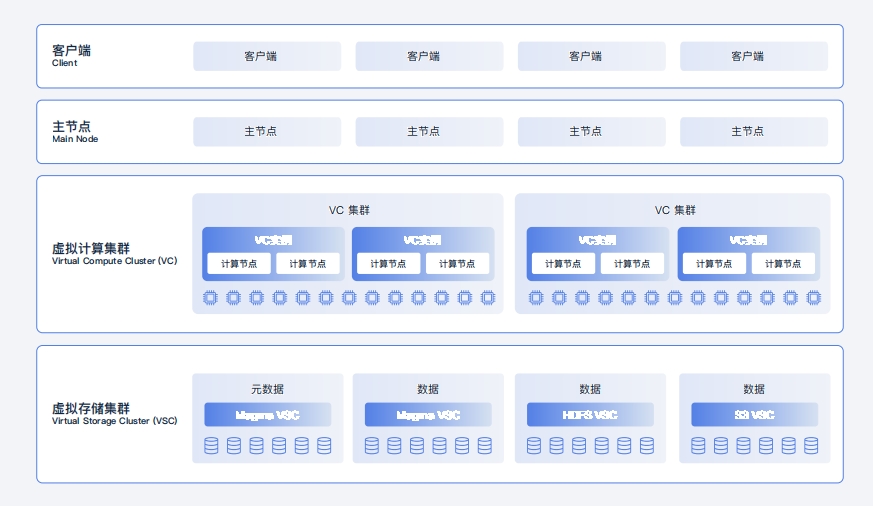
数据库向云原生架构发展兼具无限扩展、超强性能与兼容性
LittleBoy自动化机器学习平台LittleBoy 自动化机器学习平台提供完整的MLOps 链路,集成数据清洗、特征工程、深度学习、AutoML、模型管理和AI服务。其可视化交互可通过拖拽、对话引导等方式帮助用户清晰直观建模。LittleRov 同时支持有监督学习和无监督学习,近百种内置算法满足不同场景建描需求。结合OushuDB高性能读写速度。LittleBoy 相比同类产品大幅提升模型收敛效率,帮助分析师和数据科学家将机器学习快速转化为业务价值
LittleBoy 实现 MLOps 全周期功能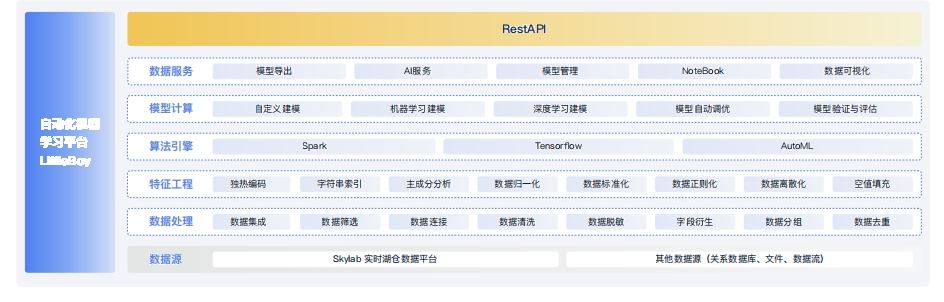
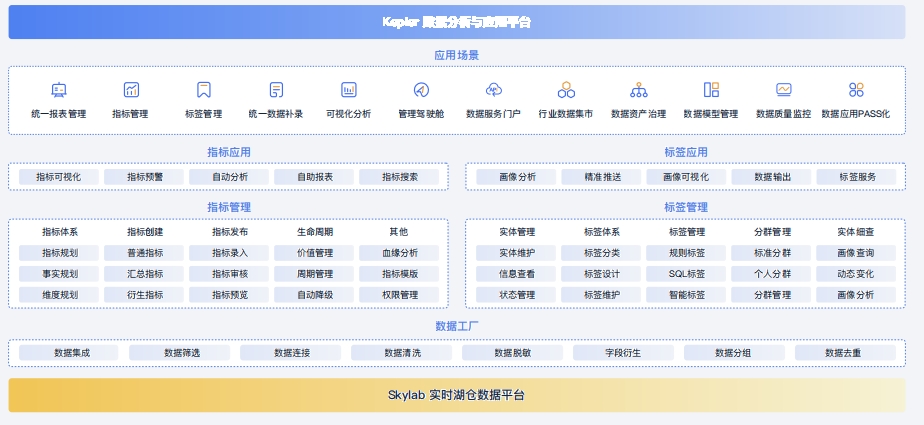
Kepler 数据分析与应用平台在传统的数据分析和应用领域,存在报表冗余、标签僵化、指标混乱,可视化繁琐等难题,为管理层决策、业务部门经营分析、IT部门数据开发,BI团队开展分析都带来极大挑战,偶数科技打造的Kepler是一款功能强大且简单易用的数据分析与应用平台,满足不同行业的数据开发、分析、应用的复合需求,通过明确标签、指标、报表、模型四种数据资产的定义及关系,Keplor将数据资产在应用维度横向打通,实现了不同类型数据资产共享,避免了数据重复开发和数据歧义。
立足于数据分析应用,Kepler通过建立数据管理与应用的抓手,结合偶数多年行业经验沉淀,重构数据管理侧,建立完善的数据资产管理机制,避免数据管理不落地的难题。Kepler还可作为 Skylab实时湖仓数据平台的访问和应用通道,在Skylab的加持下,Kepler将海量数据分析与应用的性能发挥到极致。
Kepler产品架构从数据接入、数据预处理,到数据维度建模、指标开发、标签开发,再到数据的可视化BI分析、数据仪表板Kepler 提供了一站式、智能化的解决方案,有效帮助企业打通并运营数据资产,真正形成企业数据价值
Orbit数据资产管理平台数据作为与土地、劳动力、资本、技术并重的生产要素,将逐步成为我国数字经济深化发展的核心引擎。Orbit 数据资产管理平台为用户提供可视化的数据资产图谱、自动化的数据资产分类、多维度的数据血缘分析,以及可持续的数据标准贯彻实施。通过对存量和新增的数据资产进行全方位的规划管理,为企业搭建领先的数据运营体系,减少数据污染和治理成本,提高数据可见性和使用效率,助力数字经济下的数据确权和定价,加快数据要素流通
Orbit数据资产可持续运营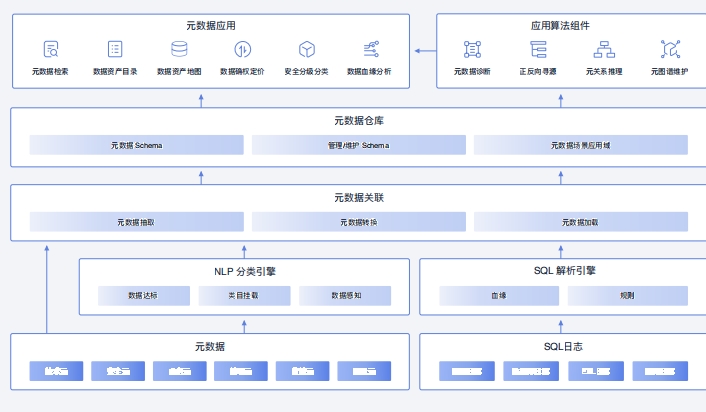
Flow数据开发与调度平台Flow 是一款拥有强大Web界面交互能力的数据开发与调度平台,为Skylab平台提供任务调度能力。Flow不仅支持丰富的任务类型,还拥有百万级任务节点的前端交互能力,灵活实现大规模集群任务的调度服务
Flow产品架构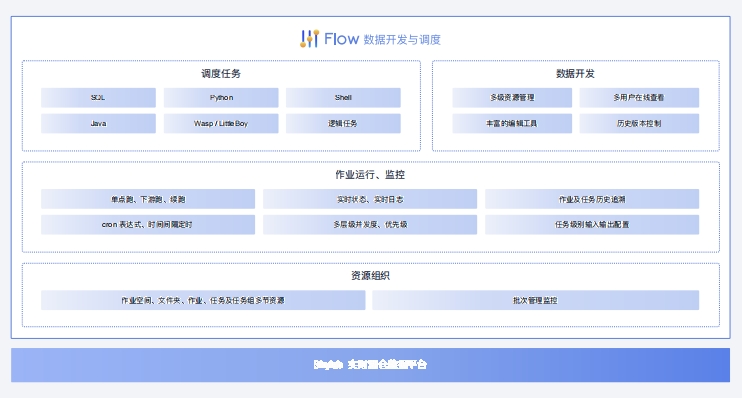
Wasp数据工厂Wasp 可以轻松对接多种数据源,灵活可扩展。支持存量和增量同步、离线和实时持续同步、自动和定时同步、数据容错和断点续传。用户可以通过零代码可视化操作进行一套任务的批流数据加工,Wasp在保证数据一致性的同时,为用户提供高性能、高春吐的数据加工和同步。
wasp实时数据同步和批流一体数据加工
Lava 系统管理软件Lava 负责 Skylab 平台集群管理、监控运维、用户管理、认证、审计、权限、消息等基础服务。通过灵活可扩展的技术架构、云中立的技术路线,为用户提供简单易用、安全可靠、性能稳定的系统管理服务,降低运维成本,提高管理效率
Lava产品架构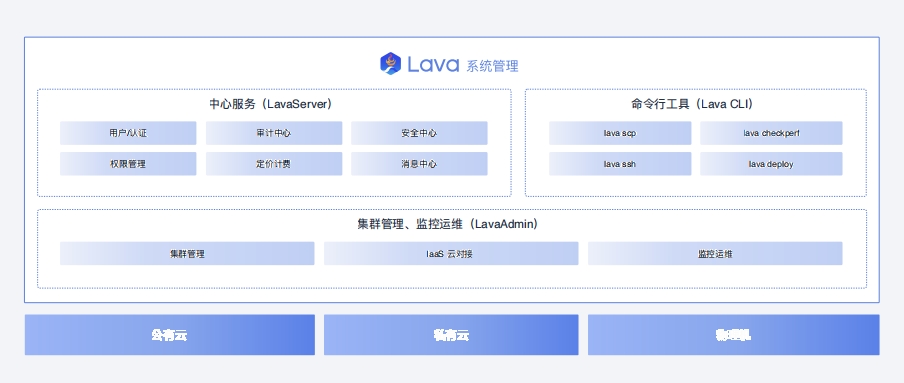
平台及行业解决方案
数据共享平台 数据资产管理 专题数据集市
机器学习平台 实时数仓平台 离线数仓平台
实时湖仓一体平台 大数据平台 跨库融合平台
自助分析方案 报表管理平台 可视化大屏
监管报送方案 智慧营销方案 数据填报系统
智慧审计方案 智能运维方案 智慧运营方案
湖仓一体的演进历程传统关系型数据库的技术架构,尤其是OLTP数据库在海量数据的存储、查阅以及分析方面出现了明显的性能瓶颈。随着分布式技术的产生和发展,出现了以 Teradata为代表的 MPP一体机数据库,以及 Greenplum和Vertica等软硬件分离的MPP数据库
2000年到2012 年,数据仓库在国内得到了广泛的推广,银行、电信等行业最早建立起数据仓库。2010年前后,大数据热推动Hadoop 技术快速普及,逐步形成了以 Hadoop 作为数据湖,MPP作为数据仓库的协作模式。这个阶段的Hadoop+MPP协作模式,即“湖仓分体”模式
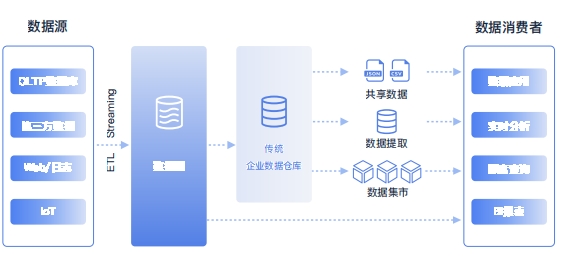
湖仓分体造成愈发严重的数据孤岛
偶数实时湖仓解决方案
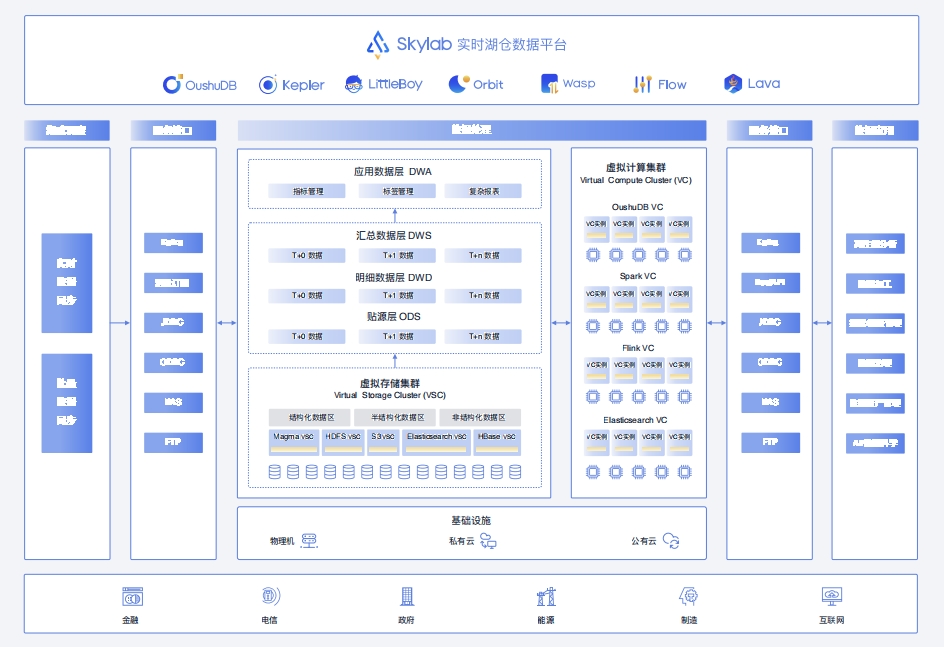
实时湖仓六大特性ANCHOR偶数实时湖仓方案真正在数据和查询层面形成一体化架构,彻底解决集群规模和并发受限、非结构化数据无法整合、建模路径冗长、数据一致性弱、性能和时效瓶颈等问题,从而帮助用户彻底规避数据孤岛,优化数据供给能效。偶数率先提出湖仓一体ANCHOR 标准,ANCHOR 中文译为锚点、顶梁柱,ANCHOR标准或将成为湖仓一体浪潮下的定海神针
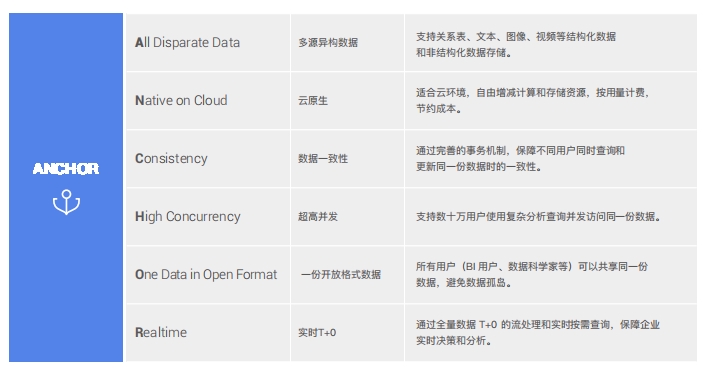
实时湖仓方案对比通过以下方案对比,可以发现基于Skylab的实时湖仓方案在技术先进性、性能和并发、功能特性、开发和运维难度等方面都具有领先优势,完全满足ANCHOR 标准,为用户节省1倍的存储成本,提高1倍的开发和运维效率
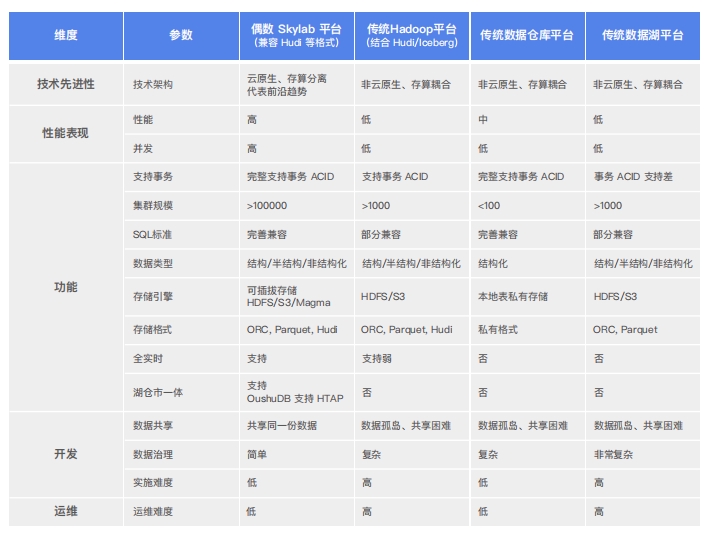
实时数据处理三大场景以一个事件发生的前后作为时间轴,可以将时间线分为三个阶段,分别是事件发生的同时、事件发生后短时间内、事件发生后较长时间,对应的实时要求分别是实时流处理、实时按需分析、离线分析。目前,实时处理有两种典型的架构:Lambda 和Kappa 架构。出于历史原因,这两种架构的产生和发展都具有一定局限性
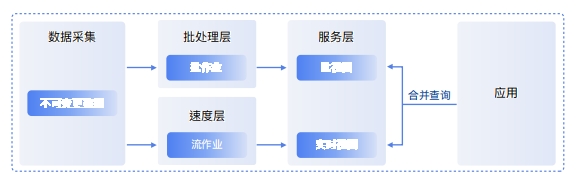
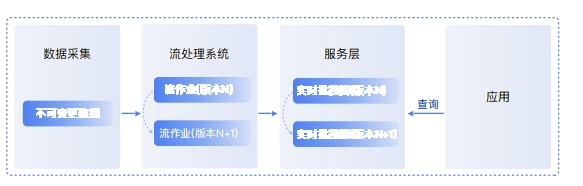
Lambda 架构Lambda 架构通过把数据分解为批处理层、速度层、服务层来解决不同数据集的数据需求,服务层通常使用MySQL,HBase等实现,供业务应用查询使用,此处的批视图就是批处理层和流处理层加工后存放于 MySQL 或HBase中的一些结果表。Lambda架构在实际落地过程中非常复杂,难以保证数据一致性,同时也很难处理可变更数据
Kappa 架构Kappa 架构在 Lambda 架构的基础上移除了批处理层,利用流计算的分布式特征,加大流数据的时间窗口,统一批处理和流处理,Kappa架构的流处理系统通常使用Spark Streaming 或者Flink等实现,服务层通常使用MySQL或HBase 等实现。Kappa 架构依赖 Kafka等消息队列来保存所有历史,而Kafka 难以实现数据的查询、更新和纠错,发生故障或者升级时需要重做所有历史,周期较长。此外,Kappa架构无法实时汇集多个可变数据源形成的数据集快照,不适合即席查询。
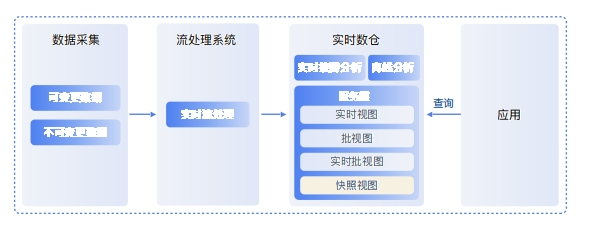
Omega 架构既然 Kappa 架构实际落地困难,Lambda 架构又很难保障数据的一致性,二者又都很难处理可变更数据,那么自然需要一种新的架构满足企业实时分析的全部需求,这就是Omega全实时架构。Omega架构由偶数科技于2021年初提出,同时满足实时流处理、实时按需分析和离线分析
Omega架构由流数据处理系统和实时数仓构成。相比 Lambda和 Kappa,Omega 架构新引入了实时数仓和快照视图,快照视图是归集了可变更数据源和不可变更数据源后形成的T+0实时快照,随着源库的变化实时变化
偶数打造的流处理系统WASP 既可以实现实时连续的流处理,也可以实现Kappa 架构中的批流一体。但与 Kappa 架构不同的是,Omega架构通过实时数仓 OushuDB存储来自Kafka的全部历史数据,规避了Kafka 难以实现数据更新和纠错的问题,大幅提高效率。此外,整个服务层可以在实时数仓中实现,无需额外引入 MySQL、HBase等组件,极大简化了数据架构
客户案例偶数已在金融、电信、能源、政企、互联网等行业的数百家头部客户形成最佳实践,并将自主研发产品出口至美国市场。帮助企业释放数据潜力,完成数字化转型
关于偶数科技偶数科技成立于2016年,是国家级专精特新“小巨人”企业。专注于云数据平台产品和解决方案,自主研发云原生分布式数据库OushuDB及实时湖仓数据平台Skylab。总部位于北京,在上海、南京、广州、武汉等地设有分支机构
产品推荐







