





 首页
首页Agora新增支持Python:视频通话中也可做图像识别了
近两年来,Python在众多编程语言中的热度一直稳居前五,热门程度可见一斑。Python 拥有很活跃的社区和丰富的第三方库,Web 框架、爬虫框架、数据分析框架、机器学习框架等,开发者无需重复造轮子,可以用 Python 进行 Web 编程、网络编程,开发多媒体应用,进行数据分析,或实现图像识别等应用。其中图像识别是最热门的应用场景之一,也是与实时音视频契合度最高的应用场景之一。
声网Agora 现已支持 Python 语言,我们还写了一份 Python demo,并已分享至 Github。本文将从 TensorFlow 图像识别讲起,并讲 TensorFlow 与 Agora Python SDK 结合,在实时音视频场景中实现图像识别。实现后的效果,如下图所示。
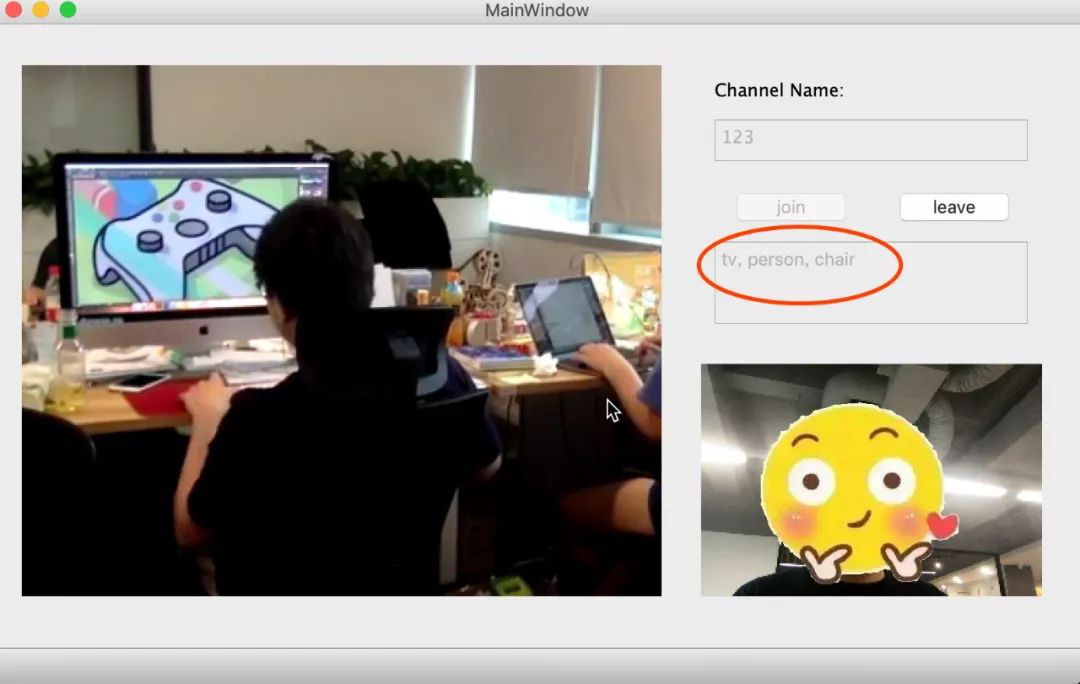
实时通话中成功识别左图中的人、椅子和显示器
TensorFlow图片物体识别
TensorFlow是Google的开源深度学习库,你可以使用这个框架以及Python编程语言,构建大量基于机器学习的应用程序。而且还有很多人把TensorFlow构建的应用程序或者其他框架,开源发布到GitHub上。所以我们今天主要基于Tensorflow学习下物体识别。
TensorFlow提供了用于检测图片或视频中所包含物体的API,详情可参考以下链接:
https://github.com/tensorflow/models/tree/master/research/object_detection
物体检测是检测图片中所出现的全部物体并且用矩形(Anchor Box)进行标注,物体的类别可以包括多种,例如人、车、动物、路标等。举个例子了解TensorFlow物体检测API的使用方法,这里使用预训练好的ssd_mobilenet_v1_coco模型(Single Shot MultiBox Detector),更多可用的物体检测模型可以参考这里:
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md#coco-trained-models-coco-models
加载库
- # -*- coding:
- utf-8 -*-
- import numpy as
- np
- import
- tensorflow as tf
- import
- matplotlib.pyplot as plt
- from PIL import
- Image
- from utils
- import label_map_util
- from utils
- import visualization_utils as vis_util
定义一些常量
- PATH_TO_CKPT = 'ssd_mobilenet_v1_coco_2017_11_17/frozen_inference_graph.pb'
- PATH_TO_LABELS = 'ssd_mobilenet_v1_coco_2017_11_17/mscoco_label_map.pbtxt'
- NUM_CLASSES = 90
加载预训练好的模型
- detection_graph = tf.Graph
- with detection_graph.as_default:
- od_graph_def = tf.GraphDef
- with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
- od_graph_def.ParseFromString(fid.read)
- tf.import_graph_def(od_graph_def, name='')
加载分类标签数据
- label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
- categories = label_map_util.convert_label_map_to_categories(label_map,max_num_classes=NUM_CLASSES, use_display_name=True)
- category_index = label_map_util.create_category_index(categories)
一个将图片转为数组的辅助函数,以及测试图片路径
- def load_image_into_numpy_array(image):
- (im_width, im_height) = image.size
- return np.array(image.getdata).reshape((im_height, im_width, 3)).astype(np.uint8)
- TEST_IMAGE_PATHS = ['test_images/image1.jpg', 'test_images/image2.jpg']
使用模型进行物体检测
- with detection_graph.as_default:
- with tf.Session(graph=detection_graph) as sess:
- image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
- detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
- detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
- detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
- num_detections = detection_graph.get_tensor_by_name('num_detections:0')
- for image_path in TEST_IMAGE_PATHS:
- image = Image.open(image_path)
- image_np = load_image_into_numpy_array(image)
- image_np_expanded = np.expand_dims(image_np, axis=0)
- (boxes, scores, classes, num) = sess.run(
- [detection_boxes, detection_scores, detection_classes, num_detections],
- feed_dict={image_tensor: image_np_expanded})
- vis_util.visualize_boxes_and_labels_on_image_array(image_np, np.squeeze(boxes), np.squeeze(classes).astype(np.int32), np.squeeze(scores), category_index, use_normalized_coordinates=True, line_thickness=8)
- plt.figure(figsize=[12, 8])
- plt.imshow(image_np)
- plt.show
检测结果如下,第一张图片检测出了两只狗狗

实时音视频场景下TensorFlow物体识别
既然Tensorflow在静态图片的物体识别已经相对成熟,那在现实场景中,大量的实时音视频互动场景中,如何来做物体识别?我们现在基于声网实时视频的SDK,阐述如何做物体识别。
首先我们了解视频其实就是由一帧一帧的图像组合而成,所以从这个层面来说,视频中的目标识别就是从每一帧图像中做目标识别,从这个层面上讲,二者没有本质区别。在理解这个前提的基础上,我们就可以相对简单地做实时音视频场景下Tensorflow物体识别。
(1)读取Agora实时音视频,截取远端视频流的图片
- def onRenderVideoFrame(uid, width, height, yStride,
- uStride, vStride, yBuffer, uBuffer, vBuffer,
- rotation, renderTimeMs, avsync_type):
- # 用 isImageDetect 字段判断前一帧图像是否已完成识别,若完成置为True,执行以下代码,执行完置为false
- if EventHandlerData.isImageDetect:
- y_array = (ctypes.c_uint8 * (width * height)).from_address(yBuffer)
- u_array = (ctypes.c_uint8 * ((width // 2) * (height // 2))).from_address(uBuffer)
- v_array = (ctypes.c_uint8 * ((width // 2) * (height // 2))).from_address(vBuffer)
- Y = np.frombuffer(y_array, dtype=np.uint8).reshape(height, width)
- U = np.frombuffer(u_array, dtype=np.uint8).reshape((height // 2, width // 2)).repeat(2, axis=0).repeat(2, axis=1)
- V = np.frombuffer(v_array, dtype=np.uint8).reshape((height // 2, width // 2)).repeat(2, axis=0).repeat(2, axis=1)
- YUV = np.dstack((Y, U, V))[:height, :width, :]
- # AI模型中大多数模型都是RGB格式训练,声网提供的视频回调数据源是YUV格式,我们做下格式转换
- RGB = cv2.cvtColor(YUV, cv2.COLOR_YUV2RGB, 3)
- EventHandlerData.image = Image.fromarray(RGB)
- EventHandlerData.isImageDetect = False
(2)Tensorflow对截取图片进行物体识别
- class objectDetectThread(QThread):
- objectSignal = pyqtSignal(str)
- def __init__(self):
- super.__init__
- def run(self):
- detection_graph = EventHandlerData.detection_graph
- with detection_graph.as_default:
- with tf.Session(graph=detection_graph) as sess:
- (im_width, im_height) = EventHandlerData.image.size
- image_np = np.array(EventHandlerData.image.getdata).reshape((im_height, im_width, 3)).astype(np.uint8)
- image_np_expanded = np.expand_dims(image_np, axis=0)
- image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
- boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
- scores = detection_graph.get_tensor_by_name('detection_scores:0')
- classes = detection_graph.get_tensor_by_name('detection_classes:0')
- num_detections = detection_graph.get_tensor_by_name('num_detections:0')
- (boxes, scores, classes, num_detections) = sess.run(
- [boxes, scores, classes, num_detections],
- feed_dict={image_tensor: image_np_expanded})
- objectText = []
- # 如果识别概率大于百分之四十,我们就在文本框内显示所识别物体
- for i, c in enumerate(classes[0]):
- if scores[0][i] > 0.4
- object = EventHandlerData.category_index[int(c)]['name']
- if object not in objectText:
- objectText.append(object)
- else:
- break
- self.objectSignal.emit(', '.join(objectText))
- EventHandlerData.detectReady = True
- # 本帧图片识别完,isImageDetect 字段置为True,再次开始读取并转换Agora远端实时音视频
- EventHandlerData.isImageDetect = True
我们已经将这个Demo 以及Agora Python SDK 上传至Github,大家可以直接下载使用。
Agora Python TensorFlow Demo:
https://github.com/AgoraIO-Community/Agora-Python-Tensorflow-Demo
Agora Python TensorFlow Demo编译指南:
- 若是 Windows,复制.pyd and .dll文件到本项目文件夹根目录;若是IOS,复制.so文件到本文件夹根目录
- 下载TensorFlow 模型,然后把 object_detection 文件复制.到本文件夹根目录
- 安装 Protobuf,然后运行:protoc object_detection/protos/*.proto --python_out=.
- 推荐使用 ssd_mobilenet_v1_coco 和 ssdlite_mobilenet_v2_coco,因为他们相对运行较快
- 提取 frozen graph,命令行运行:python extractGraph.py --model_file='FILE_NAME_OF_YOUR_MODEL'
- 最后,在 callBack.py 中修改 model name,在 demo.py 中修改Appid,然后运行即可
请注意,这个 Demo 仅作为演示使用,从获取到远端实时视频画面,到TensorFlow 进行识别处理,再到显示出识别效果,期间需要2至4 秒。不同网络情况、设备性能、算法模型,其识别的效率也不同。感兴趣的开发者可以尝试更换自己的算法模型,来优化识别的延时。
 更多产品了解
更多产品了解
欢迎扫码加入云巴巴企业数字化交流服务群
产品交流、问题咨询、专业测评
都在这里!


热门数字化产品






抖音算法推流核心指标是互动率而非GMV。天志互联直播抽盒系统从订单秒级上屏、一键拆盒、氛围引爆三个维度拉高互动率,驱动算法推流的正循环。

从"换皮联名"到"游戏化体验共创"——拆解彩棠敦煌联名案例的壁画修复小游戏设计逻辑、奶茶品牌联名翻车教训和中小品牌三条低成本高ROI的IP联名路径。

低代码时代品牌游戏化运营体系的"乐高式"搭建指南——从选模板、搭积分闭环、数据迭代到多活动并行管理和团队交接的全流程实操方法。

一个快消品牌用游戏化方法三个月救活240个死群的完整复盘——从签到排行榜、互动任务、习惯养成到赛季制防疲劳的六周运营节奏拆解。

游戏化社交裂变的三个底线原则深度拆解——让转发不像广告、让奖品有炫耀价值、给用户不转发的自由,加3%超级用户识别策略和三个常见翻车点避坑指南。