






腾讯云TI-OCR训练平台
 首页
首页 传统 OCR 深度学习模型
传统 OCR 深度学习模型 OCR 大模型
OCR 大模型 OCR 大模型的特点
OCR 大模型的特点 OCR 大模型适用场景 -- 票据识别
OCR 大模型适用场景 -- 票据识别识别票据单据、证书执照等:手写体难识别、套打/印章/水印干扰等痛点,票单据自动录入业务下自动识别汇票、回单等结构化信息,银行开户场景、保险审核场景下的用户证照识别较验,物流运送场景下中英文运单关键信息提取。

OCR 大模型适用场景 - 表格识别识别表格:表格结构复杂、栅栏线/套打/印章/水印干扰等痛点,金融银行场景下的账户流水、申请登记表等,理赔场景下的申请资料单等。

OCR 大模型适用场景 - 文档识别识别文档:文本段落较长、待提取内容存在跨行跨页、需对文档内容进行理解等痛点,各场景类型的合同文件等,商户入驻场景下的承诺函首页等。

OCR 大模型适用场景 -- 自然场景识别识别自然场景图片:拍摄背景复杂、拍摄文字扭曲等检测识别业界难点,企业入驻审核场景下的门头照识别、水印公司信息识别,工业质检场景下的电线规格、铭牌信息、零部件规格说明书等,物流快递领域下的集装箱规格、电子显示屏读数等。

腾讯云 OCR 大模型家族 DocLM--端到端文档图像理解
DocLM--端到端文档图像理解图像到文字直接生成,内容感知和具体任务解耦。单模型 & 多任务:单模型支持多种类型任务,任务间能力互补。效果更好 & 场景泛化:结构化指标更优,支持自然场景。数据 & 推理成本低:与多阶段结构化方案持平。


DocLM 核心技术 DocLM模型效果
DocLM模型效果全新自研端到端算法方案,单模型支持多种类型任务,任务间能力互补。支持自然场景结构化〔曲文、电表度数读取、门头提取、线缆规格提取等〕。支持指定形式的输出〔排版、仅输出手写等),支持套打/印章/水印等干扰场景信息提取。
 DocQA--阅读理解问答
DocQA--阅读理解问答阅读理解任务能力同步提升:结构化&阅读理解,基于检索的知识库问答

DocQA 核心技术支持长文档问答:通过Embedding模型将文档向量化成知识库,将问题向量与知识库向量匹配结果送入LLT;文档自监督预训练:增加Пext Token Prediction自监督任务,提升文本表征能力;指令微调:在不破坏LL原有特性的条件下引导模型基于上下文回答,提升信息提取准确率;低参数量微调:以较小的可训练参数优化模型,提高准确率并避免灾难性遗忘;引入布局特征:提升模型对无序输入的跨内容感知能力。
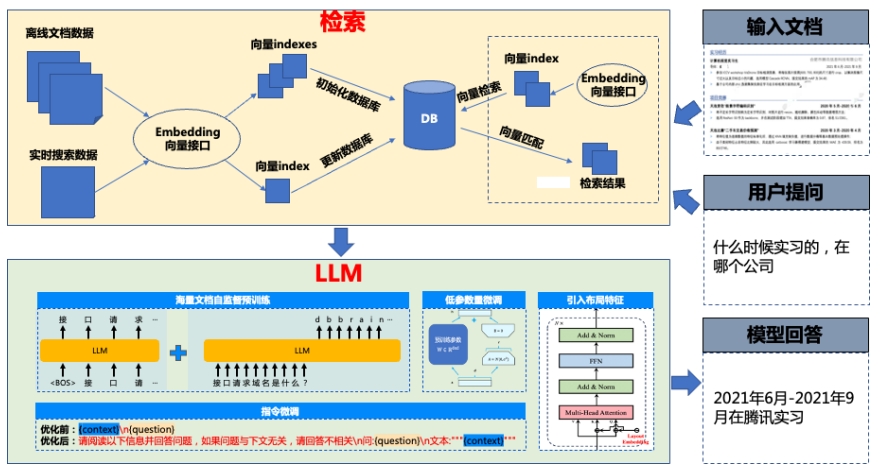
DocQA 模型效果支持信息抽取、文本摘要,具备较强的理解能力,应用于腾讯云官网封闭式问答场景中,阅读理解准确率大幅提升。


MLLM--多模态大模型从支持自然场景扩展至文档场景,Few-Shot Learning(ICL)在结构化等任务上表现优异

MLLM 核心技术 MLLM 模型效果
MLLM 模型效果聚焦泛化场景的文字理解,支持开放问答:问题理解透彻,笞案流畅度高,支持ICL:根据少量几张图片及问答对示例,理解意图并做出正确预测,完成快速场景适配,具备归纳和理解能力。

TI-OCR 支持 OCR 大模型精调DocLm会作为TI-OCR上的内置模型提供绐客户进行自定义业务下的训练精调,在压缩模型体量、节省训练成本、降低推理成本基础上,进一步提升特定场景下的OCR大模型指标。

TI-OCR 支持 OCR 大模型精调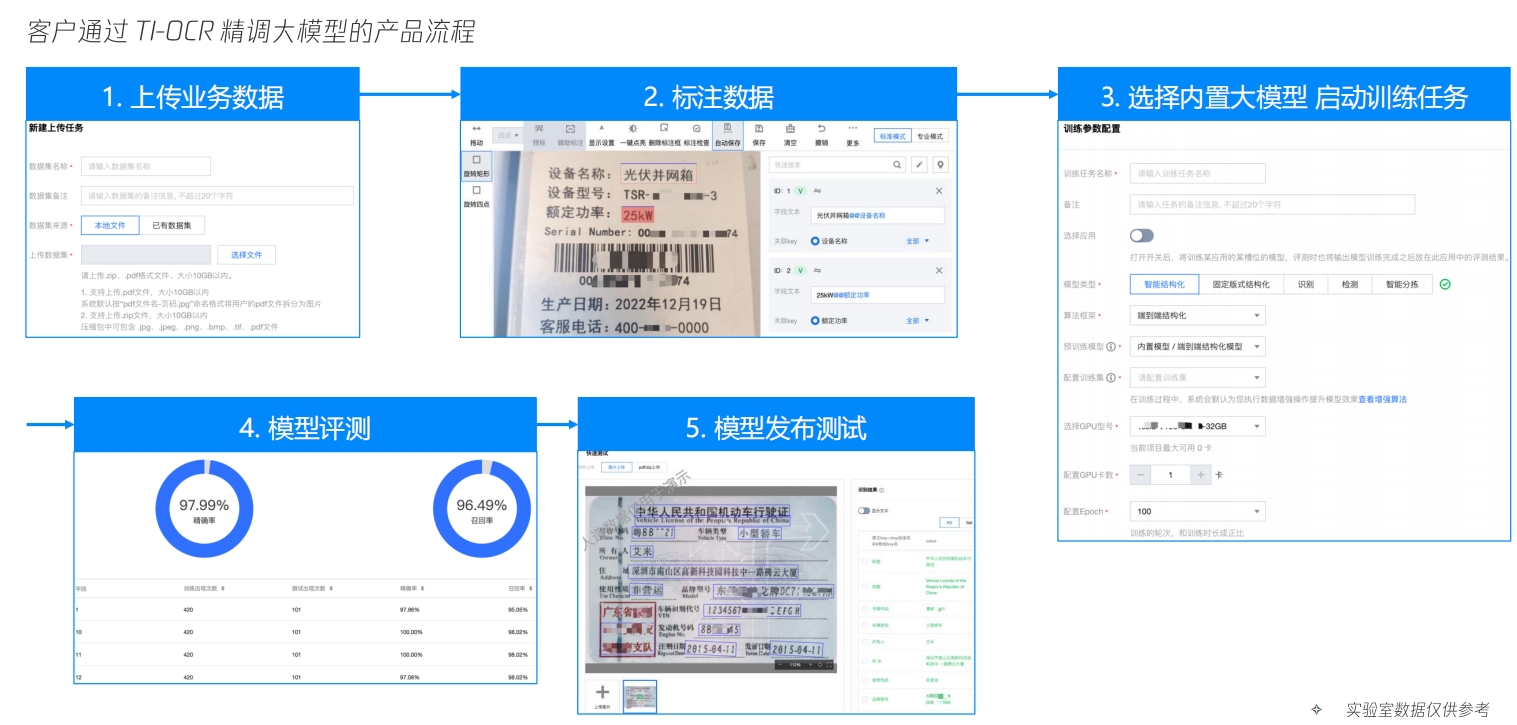 OCR 大模型精调所需资源
OCR 大模型精调所需资源 典型案例
典型案例 典型案例
典型案例大模型轻松解决曲文、水印、检测识别难例问题,各业务场景综合指标达98.6%+

典型案例大模型解决自然场景下的识别难题,审核业务机器转人工占比降低80%。在商户入驻场景下,通过引入OCR大模型自动化申请材料的照片审核,有效降低机器转人工的比例,加速商户自助办理业务的流程。

产品推荐







