






腾讯云qGPU容器
立即咨询
 首页
首页 GPU当前现状
GPU当前现状 GPU 共享方案拦截分析
GPU 共享方案拦截分析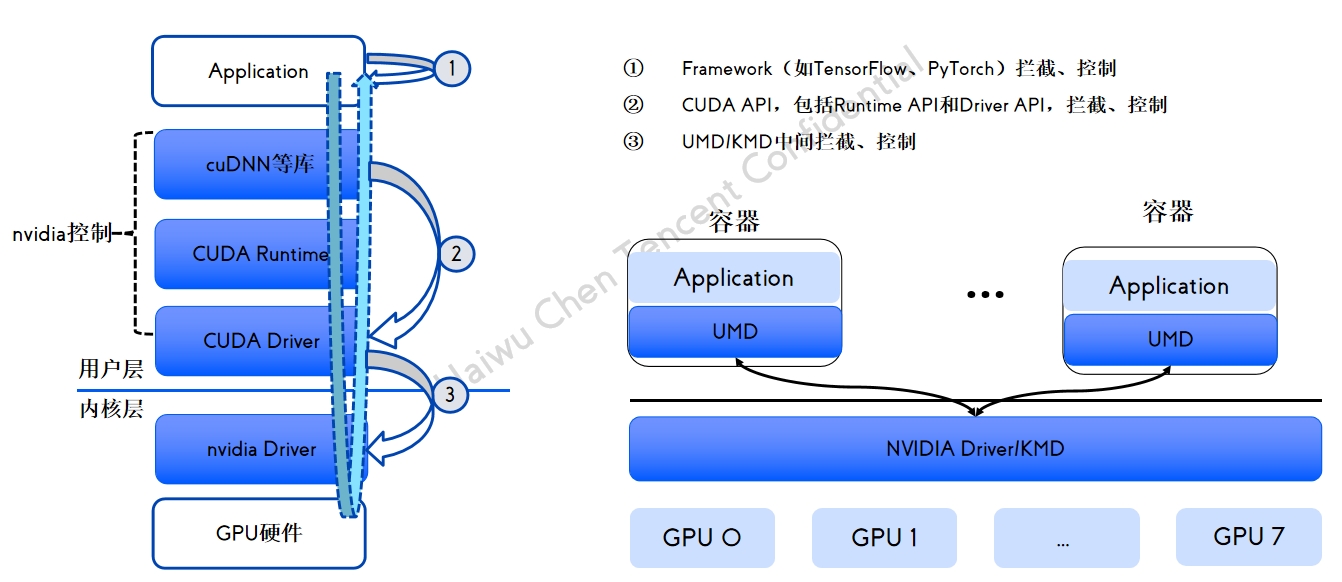 qGPU 容器产品介绍
qGPU 容器产品介绍 qGPU调度策略
qGPU调度策略
 qGPU 单卡调度policy
qGPU 单卡调度policy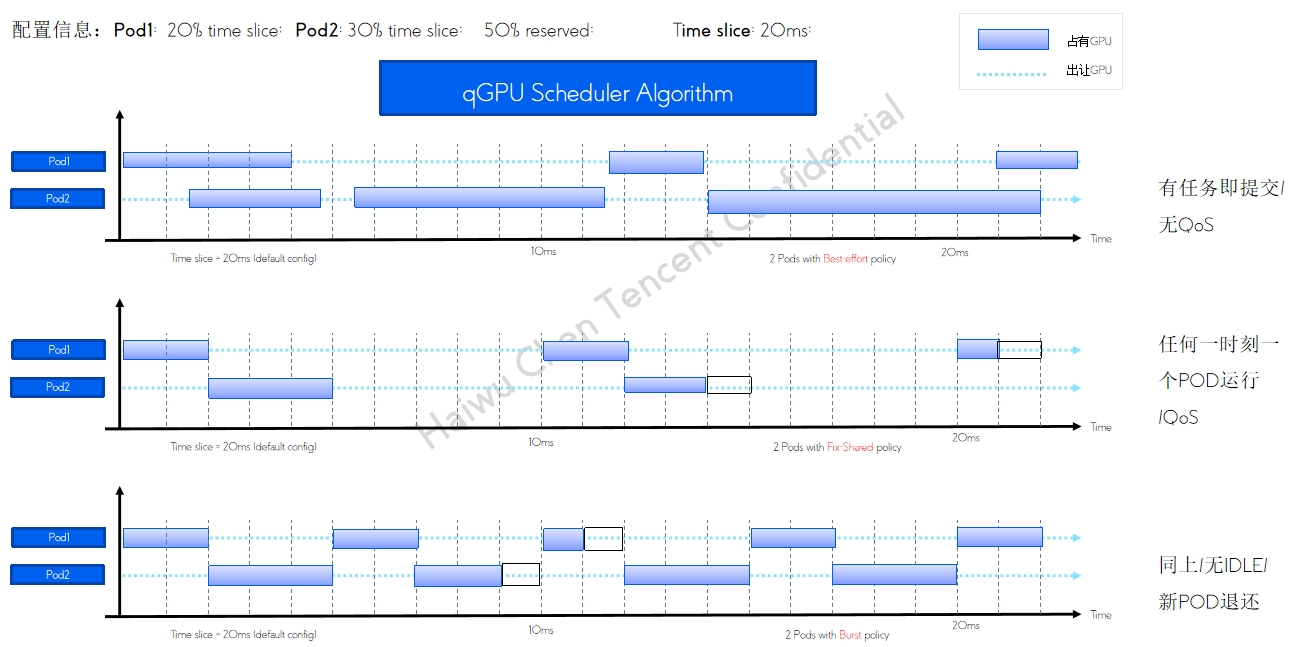 qGPU 在离线混部及调度方式
qGPU 在离线混部及调度方式高优任务 平均分配 保证负载均衡 低优任务 尽量填满 保证资源利用率 支持在线 100% 抢占 GPU利用率的极致提高 业内唯一GPU在离线混部技术

支持主流OS版本 qGPU交付方式
qGPU交付方式 qGPU IDC交付件
qGPU IDC交付件 公有云使用qGPU
公有云使用qGPU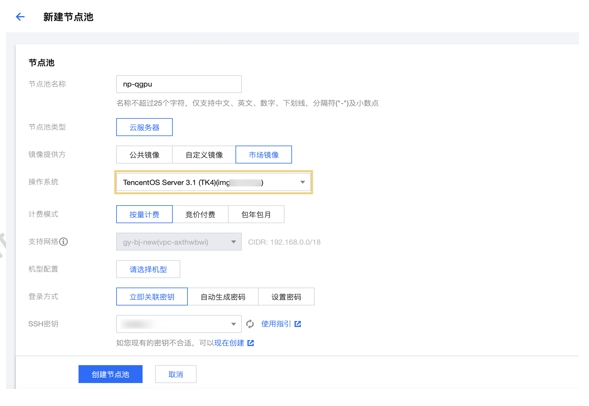 qGPU监控组件elastic-gpu-exporter
qGPU监控组件elastic-gpu-exporter 使用限制案例一:某头部互联网企业OCR场景
使用限制案例一:某头部互联网企业OCR场景 案例二:某在线教育AI推理业务
案例二:某在线教育AI推理业务
产品推荐

CODING DevOps包括代码托管、项目管理、测试管理、持续集成、制品库等多款产品和服务,涵盖软件开发从构想到交付的一切所需,使研发团队在云端高效协同,实践敏捷开发与 DevOps,提升软件交付质量与速度。

蜂创科技玩具行业数字化解决方案,搭建完整私域运营闭环,覆盖线下门店、公众号、营销活动三大引流路径,高效汇聚品牌私域流量。打通线上线下统一会员留存,依托社交运营促活用户,聚焦精准客群搭建新消费场景,助力玩具品牌沉淀用户资产,持续提升复购与销售转化。

燃创科技全行业商家经营管理系统,整合电商私域管理系统、门店会员管理系统及多商户商城搭建系统。可助力商家搭建多商户商城、运营电商私域流量、精细化管理门店会员,覆盖线上线下经营场景,打破数据壁垒,提升客户粘性与经营效率,适配全行业商家数字化运营需求。

数字化社区
视频
文章



