






腾讯云专有云TCS容器平台
 首页
首页 传统企业信息化体系存在的问题构建云原生容器平台驱动力
传统企业信息化体系存在的问题构建云原生容器平台驱动力 TCS平台组成
TCS平台组成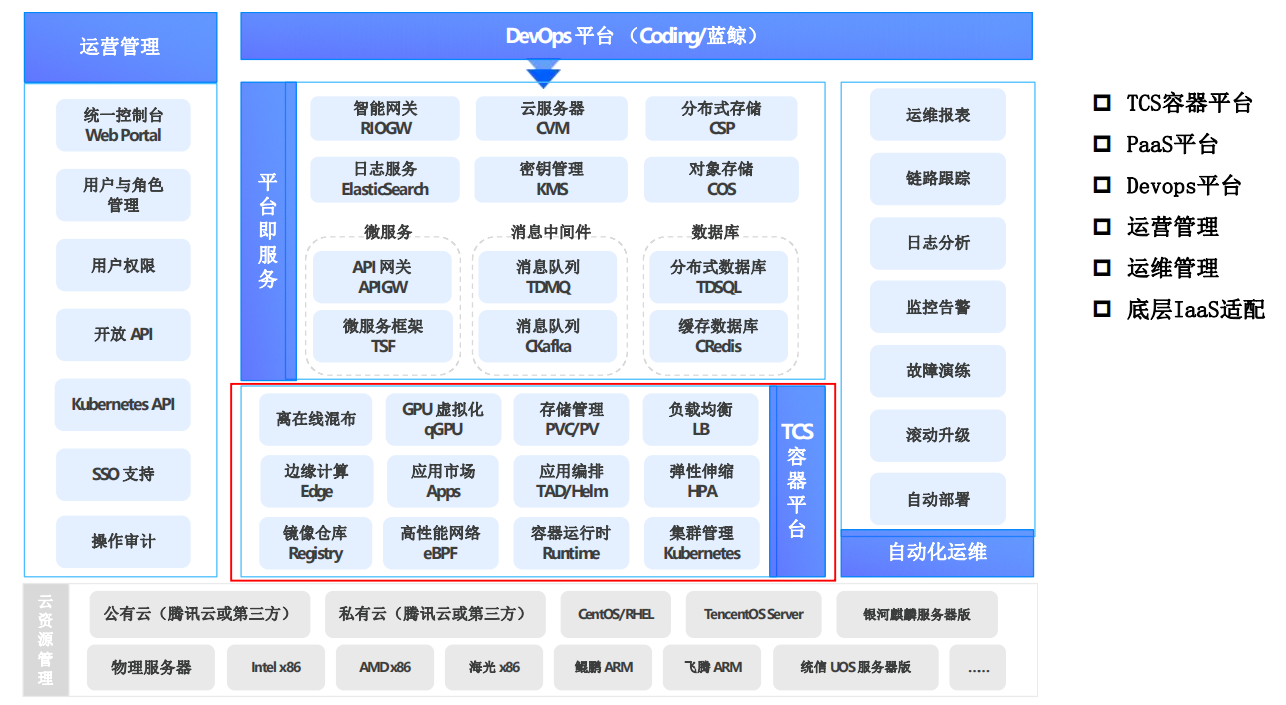 容器平台基础能力
容器平台基础能力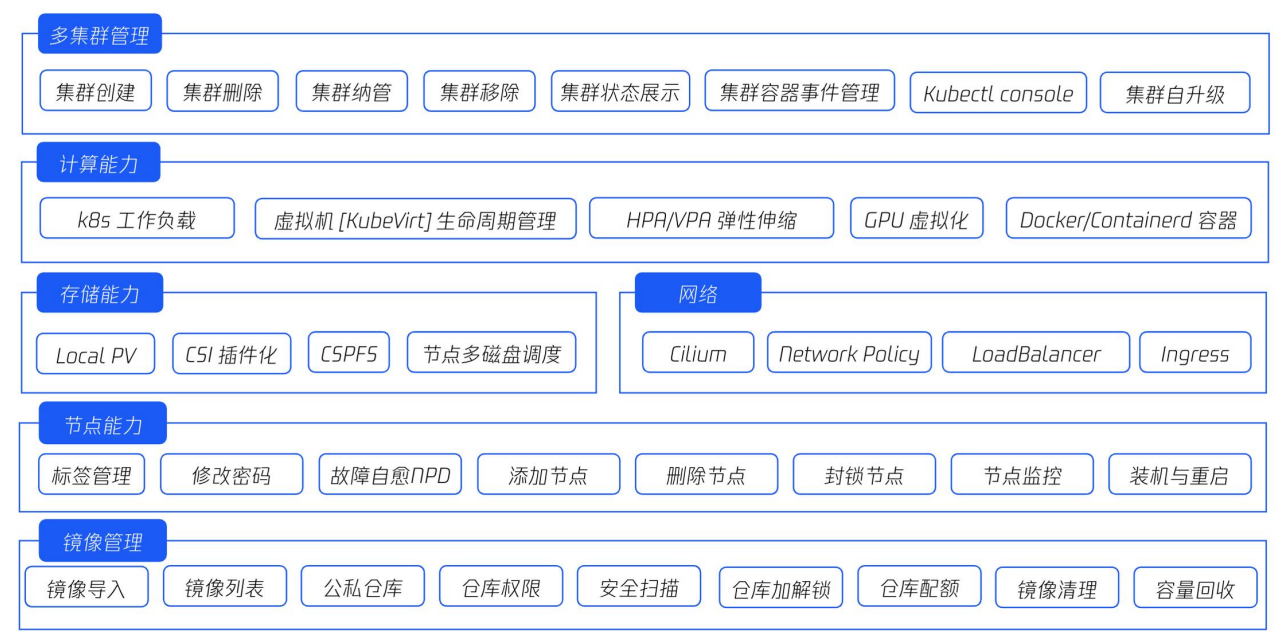 TCS容器平台部署架构
TCS容器平台部署架构 TCS容器平台优势底层资源解耦能力
TCS容器平台优势底层资源解耦能力 计算-自研有状态管理控制器
计算-自研有状态管理控制器StatefulSetPlus是一种Kubernetes CRD(Custom Resource Definition),它继承了Kubernete StatefulSet所有核心特性,核心特性包括:兼容StatefulSet所有特性。支持分批灰度更新和一键回滚,每个批次更新时,Pods是并发更新的。支持HPA(HPAPlus-Controller)。支持Node失联时,Pod的自动漂移(StatefulSet不支持)。支持容器原地升级。所谓原地升级,就是在应用升级过程中避免将整个 Pod 对象删除、新建,而是基于原有的 Pod对象升级其中某一个或多个容器的镜像版本。在原地升级的过程中,仅仅更新了原 Pod 对象中foo 容器的 image 字段来触发 foo 容器升级到新版本。而不管是 Pod 对象,还是 Node、IP 都没有发生变化,甚至 foo 容器升级的过程中 bar 容器还一直处于运行状态。在发布时配置各个批次更新副本的百分比,比如第一批10%,第二批30%, 第三批30%,第四批30%。StatefulSetPlus-Operator会根据Readyness探针完成情况,自动进行下一批次的更新。

计算-基于kubevirt的虚机资源管理 计算-GPU虚拟化
计算-GPU虚拟化 计算-腾讯vGPU
计算-腾讯vGPU 计算-腾讯vGPU
计算-腾讯vGPU 计算-腾讯qGPU
计算-腾讯qGPU 计算-Pod自动伸缩
计算-Pod自动伸缩 网络-增强能力总览
网络-增强能力总览 网络-自研高性能负载均衡TCS LB
网络-自研高性能负载均衡TCS LB4层负载均衡:LVS 或 TCS-LB,7层负载均衡:Nginx。
网络-TCS LB用户通过 Yun API 或者 提交 Service 到集群中,YunAPI 和 service controller 会创建 LB CR。控制面组件 Watch 到 LB CR 创建时:Director Manager 中的 IPAM 组件会为 LB 分配 VIP,Tunnel Controller 为 RS 配置隧道。Director Daemon 中的 Health Checker 开始探测 RS 健康,健康的RS会被 Forwarder 配置转发规则到 BPF Map 中。

网络-TCS LB BGP宣告 网络-TCS LB IPIP模式
网络-TCS LB IPIP模式 网络-TCS LB 跨az高可用
网络-TCS LB 跨az高可用 网络-基于ePBF的高性能转发
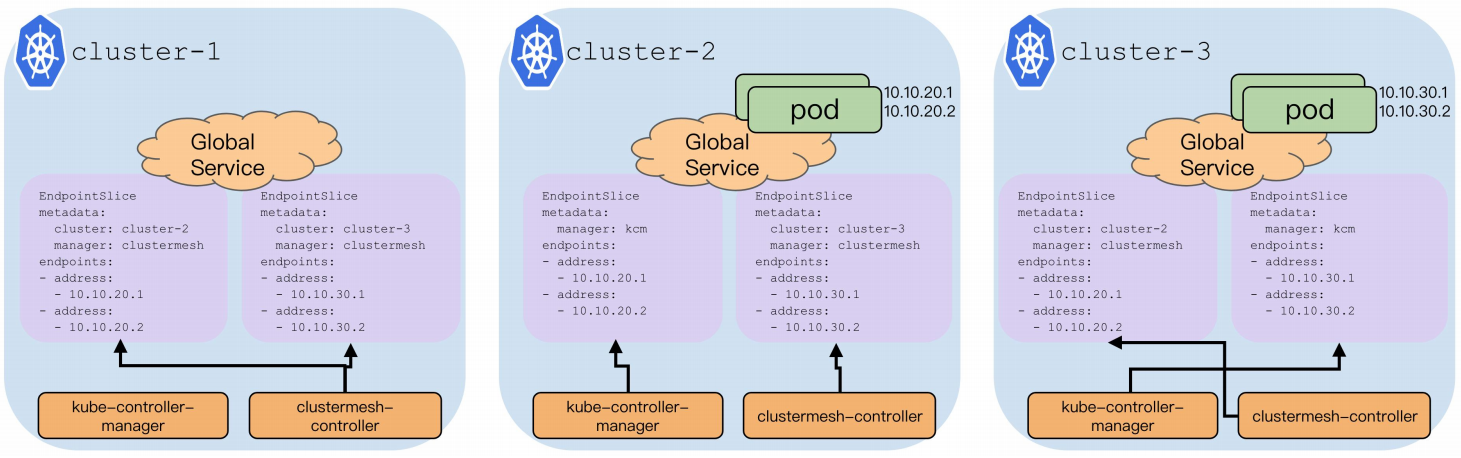
网络-基于ePBF的高性能转发 网络- ClusterMesh 跨集群服务发现和访问
网络- ClusterMesh 跨集群服务发现和访问可以将服务跨多个集群的部署,每个集群内运行相同的副本,一旦失败,请求转移到其他可用集群,该跨集群服务依旧可以通过相同的域名被正常访问。

网络- ClusterMesh 跨集群服务发现和访问Overlay 网络场景下,由 cilium-router 负责本 Node 上建立到其他 Node 的 IPIP 路由规则。

网络- ClusterMesh 跨集群服务发现和访问将 Global Service 的 EndpointSlice 同步回本集群,网络插件根据多个 EndpointSlice 来做 Service IP 的服务转发。
网络-高性能Ingress网络-高性能Ingress 集群管理-节点异常监测与自愈
集群管理-节点异常监测与自愈在Kubernetes日常运行过程中,会出现各种各样的问题,例如:1、节点docker daemon 夯死,导致节点上面的pod异常,影响在线服务。2、节点硬件故障比如CPU,内存,硬盘故障,导致在线服务异常。3、Pod所在节点的内核、CRI运行时等出现问题,无法支持Pod的运行,影响在线服务。4、节点系统内核死锁, ntp等服务异常,导致系统异常。这些问题 kubernetes 自身无法及时感知,在kubernetes集群上,通常我们只是管制集群本身以及容器的稳定运行。但是这些稳定性都是强依赖节点node的稳定的。可是node的管理,在kubernetes是比较弱的,因为可能对于kubernetes的初始设计来说,这些应该是IaaS的事。但是随着kubernetes的发展,它越来越变成了一个操作系统,它管理的内容将越来越多,所以对于node的管理也将纳入kuberntes里管理。
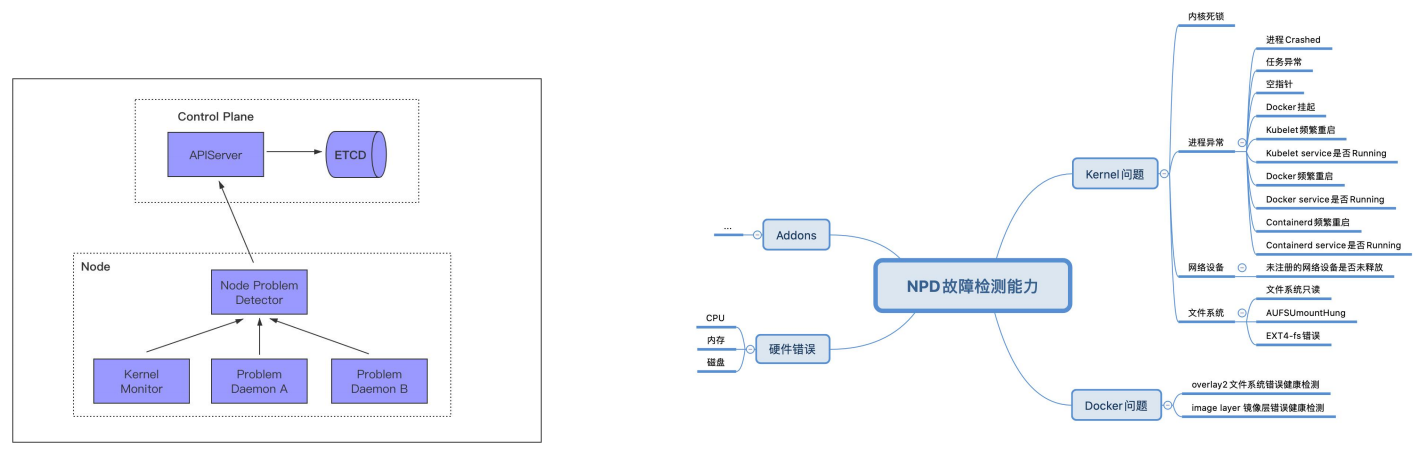
集群管理--Clusternet多集群应用治理(扩展)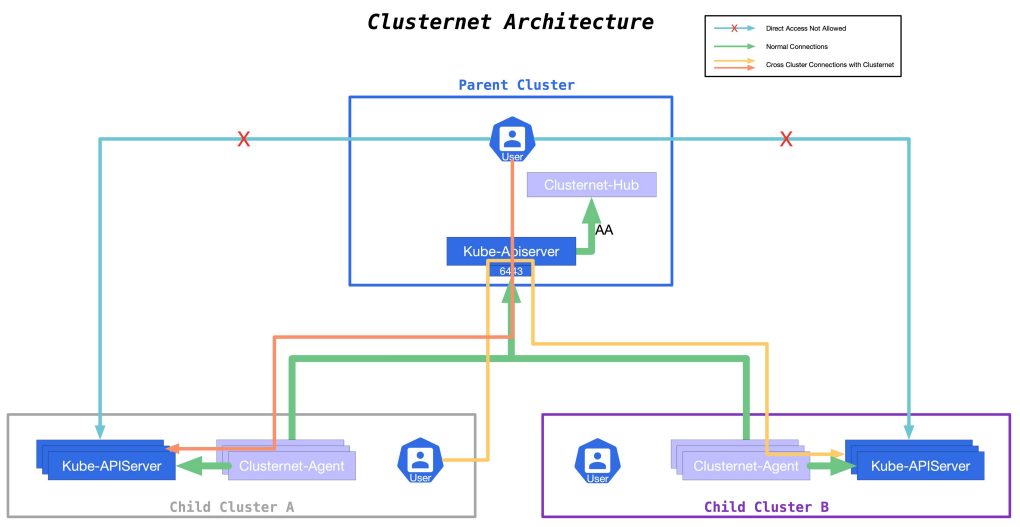 集群管理--Clusternet多集群应用治理(扩展)
集群管理--Clusternet多集群应用治理(扩展) 容器安全
容器安全腾讯云容器安全服务(Tencent Container SecurityService, TCSS)提供容器资产管理、镜像安全、运行时入侵检测、安全基线等安全服务,保障容器从镜像生成、存储到运行时的全生命周期安全,帮助企业构建容器安全防护体系。


应用编排能力-TAD单个应用可以一次声明多次部署/一键部署,组件面向终态运维和管理,兼容容器化和非容器化应用部署。

应用编排能力-应用及TAD部署流程用户先编辑TAD模板,然后按模板定义提交部署申请。部署申请提交后,应用中心将按模板定义自动完成应用的部署以及中间件的创建。

应用编排能力-应用模板编排及发布 应用编排能力-应用及TAD部署流程
应用编排能力-应用及TAD部署流程 应用编排能力-在离线混部
应用编排能力-在离线混部这两种类型的服务负载在分时复用、资源互补上存在极大的优化空间,使得它成为混部的首选场景。在离线混部:将在线服务和离线作业部署到同一个节点,以此来提高资源利用率,减少企业对与日俱增的离线计算资源的成本开支。在离线混部最重要的目标:在提高单机资源利用率的同时,保障在线服务和离线作业的服务 SLA。

应用编排能力-在离线混部挑战应用编排能力-在离线混部方案方案概述:调度保障:采用快感知慢回退预测算法、离线大框、共享状态调度等手段,进行资源弹性复用,解决调度冲突。资源保障:通过应用优先级划分、内核增强、干扰检查、超线程避让等关键手段,保证应用间资源隔离。

应用编排能力-在离线混部调度保障采取混部节点自动上报扩展的离线资源,离线服务通过离线 Cgroup 大框隔离的方式来保证资源的弹性复用和回收。首先,在资源复用的方式上,将空闲的在线资源进行精准预测,并通过扩展资源的方式,暴露给离线调度器,从而让离线调度器可以看到有多少离线资源是可以复用的,然后进行调度。其次,资源复用以后,需要能够有一层限制,限制离线负载不能过度使用宿主机的资源;在底层资源限制上,针对在线和离线业务,分别限制其在不同的 Cgroup 层级上:

应用编排能力-在离线混部调度增强多调度器共享状态调度的模式,第一是解决在线资源的复用调度问题,第二是解决调度冲突、调度性能、可扩展性和可靠性。共享状态调度,无论从资源视图共享性,并发性,资源分配的灵活性以及对多调度器的灵活支持,都表现比较出色。因此,采用共享状态乐观并发的调度方式,该方案对协调器的性能和可靠性有较高要求,但是可以做到真实的资源共享,资源视图和全局一致性,同时还能支持部署多个不同的调度器来针对不同场景进行调度。设计和实现了 调度协调器,Kubernetes 调度器只需要在reserve 阶段,开发扩展插件,进行 reserve 的提交,即可完成共享状态并发。

应用编排能力-在离线混部快感知慢回退预测算法在资源的预测和负载处理上,采用指数衰减滑动窗口算法,达到快速感应资源上升,慢速感应资源下降的目的,做到自动化,细粒度的分时复用目标。之所以需要快速感应到资源上升,是因为在线服务负载如果有上升,一般都是比较短暂的,此时需要快速感知,从而快速做出资源回收和离线退位。而在负载下降的过程中,一般不能立即就去减小在线服务的资源,而是要保证其运行一段时间,确认是负载真实的进入平稳状态,离线才能开始复用在线资源。

应用编排能力-在离线混部资源保障在单机资源保障上,结合 TencentOS 内核,提供了全维度的资源保证;在 Kubernetes 和内核侧提供了强有力的资源隔离和保障机制。在优先级上,采用精细化的 cpuset 编排技术,根据不同类型的服务优先级,高优在线业务,将其进行 cpuset 绑核。中优在线业务,采用 Cgroup quota 和 cpushare 进行 CPU 资源共享。离线业务,则采用离线大框将所有离线业务划分在一个离线 Cgroup 资源池下,但是可以去使用所有的 CPU 核,也可以支持离线业务单独绑定在和高优在线业务完全互斥的 CPU 子集下。

应用编排能力-在离线混部资源保障除了基于传统 Cgroup 限制与隔离,比如采用 CPU quota、CPU share 进行资源的限制和隔离,采用 cpuset 进行绑核等,也在内核层次上进行了充分的定制和优化,以适应云原生场景。在 CPU 方面,为了在微观层次应对突发流量以及超线程干扰,TencentOS 云原生内核支持选取 BT 调度类进行离线任务调度,从而能够实现在内核级快速减少离线任务干扰,同时能防止离线任务出现饥饿状态。在内存方面,TencentOS 内核拥有 Cgroup 级别的 cache 清理功能,及时释放某个容器的 cache, 比如离线业务完成以后,就可以将其 pod 触发的 page cache 进行及时清理。在网络和磁盘 IO 方面,云原生内核都进行了自研控制,接口都是标准 Cgroup 接口,充分利用相关 qos 进行容器的qos 保证。

应用编排能力-在离线混部干扰检查业务的 SLO 干扰检查,一方面是系统层次的指标的干扰检查,另一方面是应用层次的指标的干扰检查。在系统层次,采集各种系统资源指标,比如感知指令集频率 CPI,感知系统调用等手段,获取系统指标干扰。在应用层次,允许在线业务设置自己的 SLO 干扰阈值,混部系统能够回调和检查业务的 SLO,一旦检查到业务真实的SLO 不符合预期,就会采取一系列措施进行干扰源消除;对于离线业务的 SLO,允许动态优先级调整以及弹性公有云的方式,避免离线业务长时间等待或者频繁驱逐,保证离线业务能够在规定时间内跑完。

应用编排能力-在离线混部业务价值跨区域高可用能力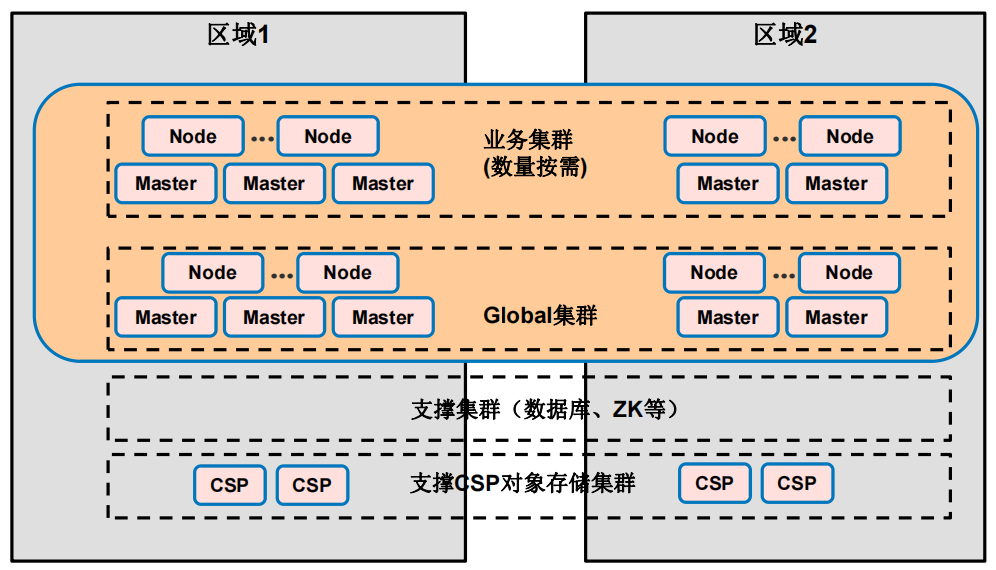 容器业务高可用部署方案
容器业务高可用部署方案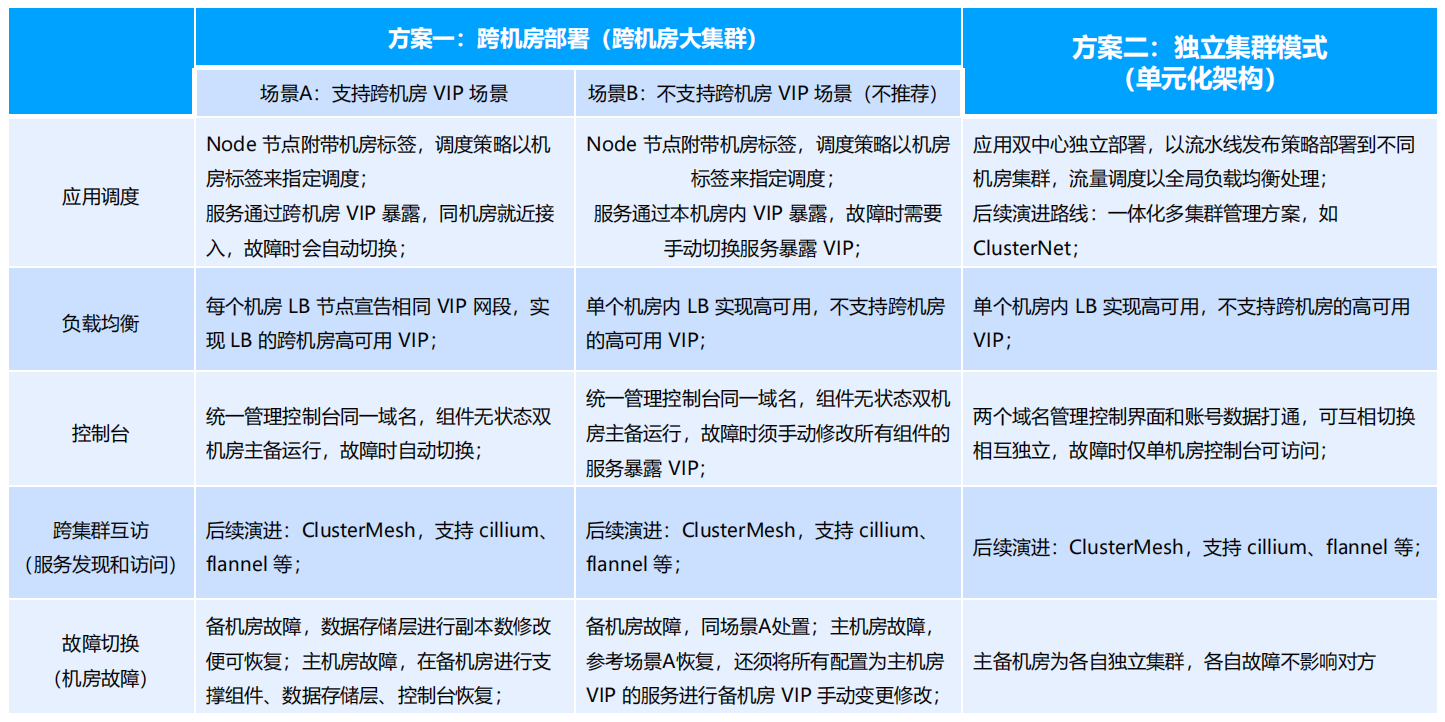 容器业务高可用部署方案1
容器业务高可用部署方案1 容器业务高可用部署方案2
容器业务高可用部署方案2 运营运维
运营运维 运营运维-角色和项目管理
运营运维-角色和项目管理用户:Tencent TCS平台的使用者。用户有不同角色,不同角色的操作权限不同,按权限访问资源。项目:Tencent TCS上的一个对象管理集合。用于资源隔离和配额限制,提升协作和管理便捷性。应用:项目内部的部署单元,对应一组业务组件。集群:Tencent TCS上的一个Kubernetes容器集群。Global集群为Tencent TCS管控集群,其它为Tencent TCS业务集群。管控集群和业务集群可分可合。不支持项目跨集群。Tencent TCS角色定义:1、超级管理员-产生管理员2、管理员-所有资源的管理者3、观察员-所有资源只读4、审计员-操作日志审计

运营运维-角色和项目管理用户:Tencent TCS平台的使用者。用户有不同角色,不同角色的操作权限不同,按权限访问资源。项目:Tencent TCS上的一个对象管理集合。用于资源隔离和配额限制,提升协作和管理便捷性。应用:项目内部的部署单元,对应一组业务组件。集群:Tencent TCS上的一个Kubernetes容器集群。Global集群为Tencent TCS管控集群,其它为Tencent TCS业务集群。管控集群和业务集群可分可合。不支持项目跨集群。Tencent TCS角色定义:1、超级管理员-产生管理员2、管理员-所有资源的管理者3、观察员-所有资源只读4、审计员-操作日志审计

运营运维-镜像仓库TCS 提供镜像的安全扫描:在镜像仓库视图中可以对现有的镜像源中的镜像进行安全扫描,包含对镜像的漏洞检测、配置文件检查等(Clair 集成)。
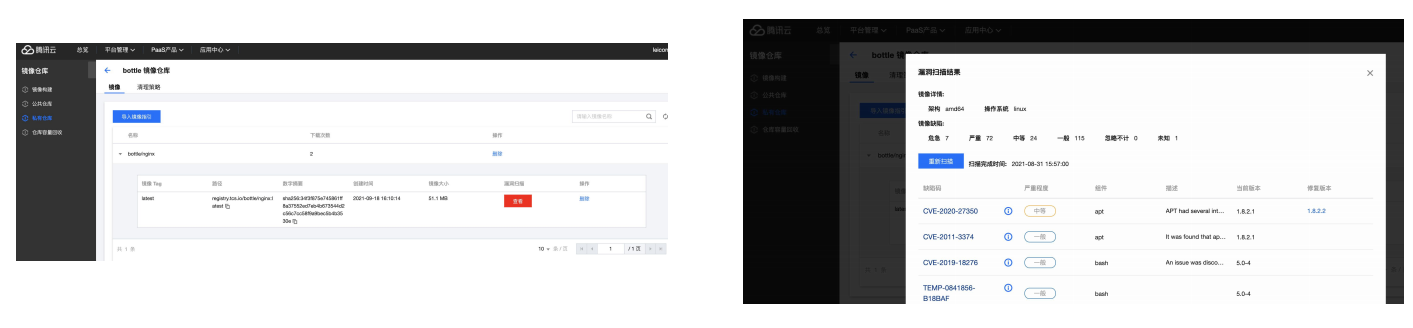
运营运维-镜像仓库可以在镜像仓库视图中查看镜像库中所选镜像的信息,可查看到镜像对应的DOCKERFILE文件信息,查看镜像分层的Layer信息。TCS 支持从镜像管理视角查找到镜像所在主机,以及基于此镜像所创建的容器。
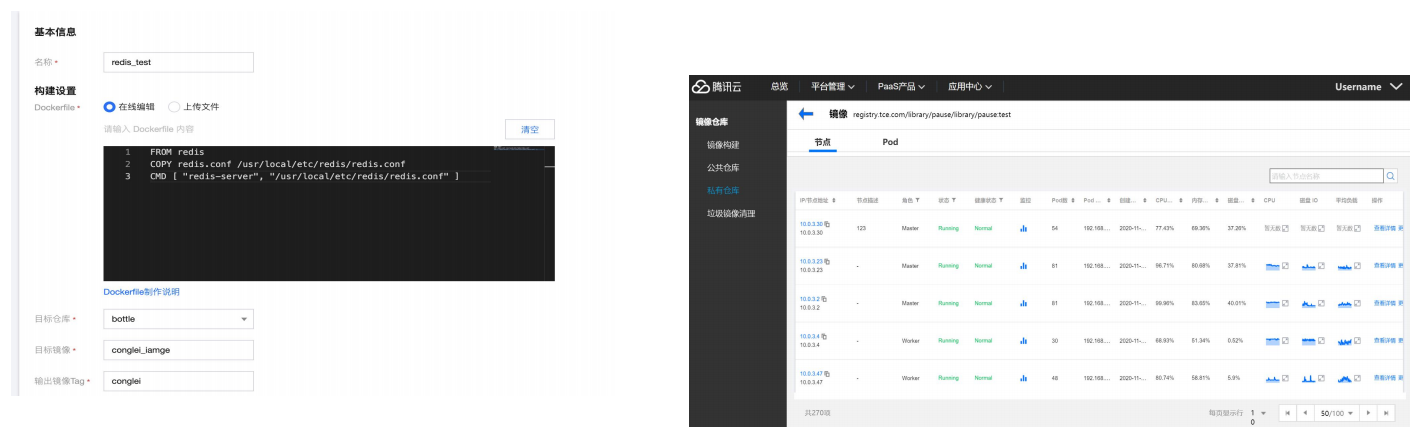
运营运维-镜像仓库可以在镜像仓库视图中查看镜像库中所选镜像的信息,可查看到镜像对应的DOCKERFILE文件信息,查看镜像分层的Layer信息。TCS 支持从镜像管理视角查找到镜像所在主机,以及基于此镜像所创建的容器。

运营运维-镜像仓库TCS 支持从镜像管理视角查找到镜像所在主机,以及基于此镜像所创建的容器。

运营运维-镜像仓库TCS提供跟进不同租户的多种权限层级的镜像仓库供用户选择,其中公共镜像仓库可以存放日常通用使用的基础镜像,而每个租户还可以创建私有仓库,私有镜像仓库默认只有创建人才能使用,而通过在私有镜像仓库上赋予用户权限,可以小团队范围内的共享镜像仓库。私有镜像仓库默认具有隔离权限,保证安全可靠,也可以通过共享镜像仓库,提供公共可用的镜像。

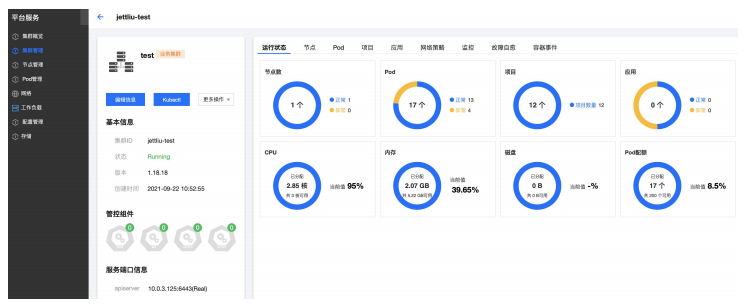
运营运维-监控TCS 平台支持提供基于Prometheus监控工具和Grafana可视化平台的监控方案,能够对平台自身组件、应用以及服务提供全栈的监控。支持K8S机器的节点、pod、容器等各层的cpu、内网等利用率监控。支持节点、pod和master组件的状态监控。支持集群流量和存储qps/时延的监控。
运营运维-日志 运营运维-日志
运营运维-日志TCS支持日志中心,包括日志的采集、索引、存储和分析,用户可以在日志中心基于loki语法进行各种组合搜索,并进行事件编排,同时也支持联动告警。

运营运维-告警通知TCS 支持集中展示k8s集群告警策略。支持告警列表查询功能,支持按类型、告警对象、状态等过滤。告警详情支持展示告警对象、触发时间、告警等级等。支持告警屏蔽。TCS 支持将平台监控、告警、事件等信息以邮箱、短信、webhook、企业微信等形式发送给已配置好的通知发送人,支持给一个通知添加多个通知方式。

产品推荐







