






阿里云通义灵码
立即咨询
 首页
首页 通义灵码核心功能
通义灵码核心功能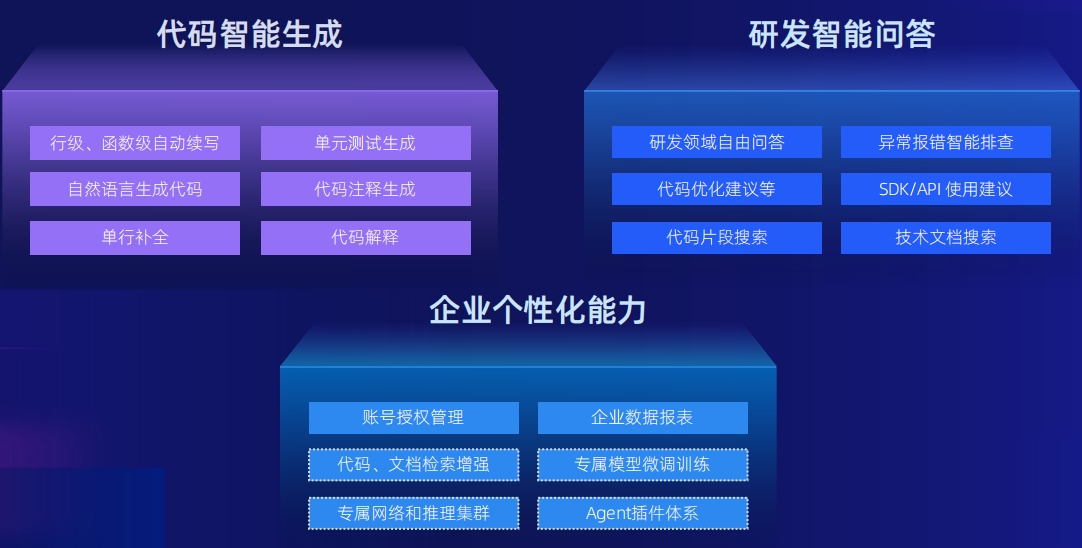 通义灵码产品架构
通义灵码产品架构
 产品亮点与优势
产品亮点与优势开发者心流体验
适配多种IDE京生观党、交互设计,更贴合开发者使用习惯;调优速度、时机、长度,打造不打扰不等待开发者码心流体验。
贴合代码库场景
客户端和模型层同步优化针对代码跨文件上下文感知能力,生成代码更加贴合当前代码库场景。
安全、可控
基于 https 加密传输,并支持身份鉴权、内容安全防护等,代码数据仅用于推理,不会进行二次训练。全方位保障数据安全,完全由你所有及控制。
沉浸式编码
IDE端内即可满足开发者编码场景中的技术资料检索、技术难题解答的诉求,打造开发者沉浸式
编码体验。
编码体验。
阿里云使用场景友好
针对阿里云的云服务使用、SDK/OpenAPI使用
等场景调优代码生成、智能问答将对阿里云的
云服务使用场景更友好。
双模引擎,自由切换
极速本地模型、云端大模型补全一键切换,满足不同网络环境不同补全强度的场景诉求。
技术先进性代码补全技术
基于库内自动感知的代码生成及问答。
基于语义理解的自适应生成粒度决策。
基于检索增强的代码生成及问答。
基于语义理解的自适应生成粒度决策。
基于检索增强的代码生成及问答。
研发问答技术
公共云千亿级参数模型+互联网RAG能力,研发问题准确率90%以上,大幅消除幻觉。
私有化支持72b模型输出,语言理解力,推理分解能力相较于小参数模型有质的提升。
私有化支持72b模型输出,语言理解力,推理分解能力相较于小参数模型有质的提升。
性能、兼容性
插件兼容性得到数十万用户验证兼容无死角,支持远程开发模式。
硬件兼容英伟达A10以上全系列GPU,兼容海光DCU、即将兼容华为昇腾。
支持多卡部署,性能表现极佳,JetBrains IDE支持流式补全。
硬件兼容英伟达A10以上全系列GPU,兼容海光DCU、即将兼容华为昇腾。
支持多卡部署,性能表现极佳,JetBrains IDE支持流式补全。
通义灵码主要市场竞争力
目前国内插件市场下载量第一,市场接受度高
通义灵码从23年11月2日云栖大会发布公测至今,在VSCode及JetBrains IDE插件市场上,下载安装数350万,目前在国内同类产品中,下载安装量第一,市场接受度高。
背靠阿里云,超强的算力资源和模型能力
通义灵码脱胎于阿里云,在大语言模型时代,算力是大语言模型的发动机,阿里云近乎无限的算力资源。同时,阿里云开源了迄今为止最大的模型,在模型能力上有很好的保障。
与 DevOps 工具链形成联动
通义灵码与阿里云 DevOps平台同属于一个产品技术团队,在研发领域有很强的技术背景,同时,结合DevOps 工具链,可形成更具竞争力的研发智能化解决方案,如代码评审,构建问题排查,代码库转RAG/SFT等能力。
产品及模型的迭代速度快
通义灵码从上线至今两个多月内,插件端迭代了十几个版本,同时模型侧以周为单位进行迭代优化,整体的迭代速度,有利于产品以更快的速度响应用户的问题及提供更好的智能化生成能力。
专属版架构
 客户实际落地效果
客户实际落地效果
企业个性化-私域数据适配场景项目管理
·所在行业存在较多专有词汇
·对需求/任务/缺陷的内容及
格式有固定的规范/要求
·需要学习已有的项目管理策
略/经验
·对需求/任务/缺陷的内容及
格式有固定的规范/要求
·需要学习已有的项目管理策
略/经验
开发
·编码需要符合企业制定的规
范
·需要引用企业内的二方包
·需要调用企业内的API接口
·代码的业务逻辑较复杂,存
在较少的通用代码
·需要适配企业内已有的数据
库表结构,并学习SQL的相
关逻辑
·企业内通常使用自研的开发
框架,如前端框架、组件库
等
范
·需要引用企业内的二方包
·需要调用企业内的API接口
·代码的业务逻辑较复杂,存
在较少的通用代码
·需要适配企业内已有的数据
库表结构,并学习SQL的相
关逻辑
·企业内通常使用自研的开发
框架,如前端框架、组件库
等
测试
·需要符合企业内指定的
测试规范
·所在行业的业务逻辑较
复杂
·企业内通常使用自研的
测试框架
测试规范
·所在行业的业务逻辑较
复杂
·企业内通常使用自研的
测试框架
运维
·需要复用企业内的运维
手册
·运维人员需要学习企业
内的大量运维脚本/知识
·需要快速获取企业内的
运维接口/API
手册
·运维人员需要学习企业
内的大量运维脚本/知识
·需要快速获取企业内的
运维接口/API
数据分析
·需要适配数据中心的海
量表结构
·需要学习已有的数据分
析/处理逻辑
量表结构
·需要学习已有的数据分
析/处理逻辑
企业个性化方案选择要点一模型微调 or RAG检索增强生成模型(RAG)
·适合场景:
1. 私域数据量庞大但不需要模型完全记住所有内容,而是需要快速检索相关信息并结合上下文生成答案的场景。
2. 对于问答系统、推荐系统等任务,其中涉及从大量文档中提取关键信息并将其与模型生成的内容相结合的情况。
·优点:
1. 结合了检索和生成的优点,模型可以在不增加参数量的情况下扩展其知识边界,通过索引检索相关片段再进行推理生成。
2. 能够减少对大量数据进行微调的需求,降低资源消耗,并具备较高的数据时效性。
·缺点:
1. 检索部分依赖于索引的质量,如果索引构建不佳或更新不及时,可能影响模型的表现。
2. 由于涉及到检索步骤,实际运行时可能会增加推理系统的复杂性和延迟时间。
3. RAG模型在处理非常专业或深度定制化的任务时不如微调模型表现得精准。
模型微调(Fine-Tuning)
·适合场景:
1. 当私域数据量较大且具有较好的领域特异性时,例如企业内部知识库、专业文档等。
2. 需要模型对私有数据的细节有深刻理解,并能根据这些数据生成准确或预测输出的任务。
·优点:
1. 可以利用预训练大模型的强大语言理解和生成能力,在特定领域上进一步提升效果。
2. 微调后的模型能够更好地捕捉和利用私域数据中的模式和规律。
·缺点:
1. 对于较小的数据集,容易过拟合,导致模型泛化能力下降。
2. 需要大量的计算资源来进行训练,尤其是对于参数量极大的大模型而言。
3. 在某些情况下,微调可能引入噪声或者潜在的安全风险,如模型被私有数据中的偏见或错误信息影响。
企业个性化能力核心流程
RAG知识管理
 基于检索增强的研发问答
基于检索增强的研发问答
 基于本地工程的研发问答
基于本地工程的研发问答
 基于私域数据微调的个性化学习
基于私域数据微调的个性化学习
 BizDevOps“副驾驶”的职责与能力
BizDevOps“副驾驶”的职责与能力
 Agent人机协同
Agent人机协同
 研发领域多智能体协同
研发领域多智能体协同
 智能项目管理
智能项目管理
 智能代码评审痛点
智能代码评审痛点
智能代码评审
 智能分层测试
智能分层测试
 智能平台工程
智能平台工程
 智能研发问答
智能研发问答统一问答入口、实时研发知识、代码文档搜索、一键唤起助手、自然语言操作、个人智能助理
 DevOps平台智能化建设方法
DevOps平台智能化建设方法
AI赋能软件开发全生命周期从需求协作到软件发布,完成整个工具体系的智能化升级

产品推荐

微三云七人拼团系统开发,聚焦平台裂变营销与超级卖货场景。提供七人拼团超级卖货APP开发服务,依托“拼团裂变+奖励分销”机制,支持多品类商品快速成团、用户自动分佣及数据实时监控,助力企业激活私域流量,低成本实现用户裂变与销量爆发式增长。

绿云软件智慧住全链路解决方案,宾客通过智慧住小程序便可自助匹配订单,完成在线人证核验,即可自动分房获得房卡,全程不超过30秒!离店退房时,使用智慧住小程序线上自助结账、自助开发票,节省客人时间。酒店接待时间大幅缩短,人员成本大大降低,同时也提升了入住体验。

埃文科技IP地址数据生活服务APP应用方案,通过IP的地理位置信息与GPS信息交叉验证,识别判断用户本次操作行为的风险程度,以保证用户账号及交易安全。根据平台/APP用户登录的IP地址,进行归属地解析,分析平台用户在不同城市、不同行政区域的分布活跃情况,并以此制定相关的用户拉新或增长策略。

oTMS 运输管理平台,专业 TMS 运输管理系统与智能物流运输管理工具。依托云平台连接运输全链条各方,实现端到端全流程管理,优化物流调度效率,提升运输可视化水平,适配多行业物流场景,助力企业降本增效,是物流运输管理的优选平台。
数字化社区
视频
文章



